Как мы будем действовать
Счетчики производительности по разному реализованы в процессорах семейства P6 (к которым принадлежат Pentium Pro/Pentium-II/Pentium-3) и Pentium-4. Никаких принципиальных различий нет, но коды счетчиков производительности и номера MSR-регистров слегка другие и код, предназначенный, для P6, попав на Pentium-4, вызывает исключение, как правило, заканчивающиеся голубым экраном смерти под WindowsNT.
Главным образом мы будем говорить про семейство процессоров P6 и в этом есть свой резон, во-первых, они в наибольшей степени нуждаются в разгоне (Pentium-4 и без того производительны), и, во-вторых, в отличии от Pentium-4 они не поддерживают автоматическое снижение тактовой частоты при перегреве, уменьшая свой разгонный потенциал. Но, как бы там ни было, перенести код с P6 на Pentium-4 сможет любой программист, даже начинающий, так что не будет отвлекаться на несущественные различия между этими платформами, а сразу перейдем к делу.
Процессоры семейства P6 несут на своем борту два счетчика производительности, физически представляющие собой внутренние 40-битные MSR-регистры — PerfCtr0 и PerfCtr1, каждый из которых может подсчитывать события определенного вида, коды которых задаются другими MSR-регистрами — PerfEvtSel0 и PerfEvtSel1 соответственно. Они же отвечают за запуск/останов счетчиков производительности.
Коды событий, которые процессор может подсчитывать, перечислены в приложении "A" руководства по системному программированию "Intel Architecture Software Developer's Manual Volume 3: System Programming Guide". В частности, событие "промах кэш памяти данных" проходит под номером 48h, а "промах кэш памяти кода" — 81h.
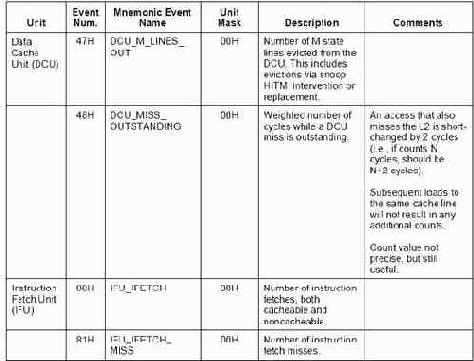
Рисунок 1 номера различных событий, за которыми можно вести мониторинг с помощью счетчиков производительности
Чтение/запись MSR регистров осуществляется командами RDMSR/WRMSR, доступными _только_ из нулевого кольца и действующими следующим образом: в регистр ECX помещается номер выбранного MSR-регистра, а в регистровой паре EDX:EAX – возвращаемое/записываемое значение.
Номера MSR- регистров так же можно узнать из руководства по системному программированию. Так например, номер регистр PerfEvtSel0 имеет номер 186h, а структура его управляющих полей приведена на рис. 1.
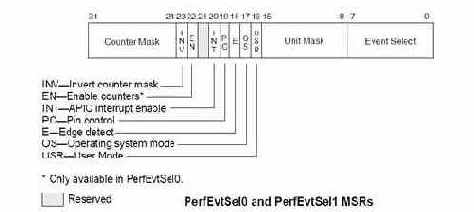
Рисунок 2 структура MSR-регистров PrefEvtSel0/ PrefEvtSel1
Собственно говоря, все, что нам нужно это занести код события в регистр PerfEvtSel0/PerfEvtSel1 (биты 0-7), маску события, в данном случае равную нулю (биты 8-15) и взвести флажок Enable Counter (бит 22), чтобы начать подсчет событий. Описание остальных битов можно найти в документации, нам они совершенно не интересны за исключением, пожалуй, поля USR (бит 16), открывающего к счетчику доступ с пользовательского уровня, позволяя реализовать основной код в программе прикладного режима, которую намного проще отлаживать чем драйвер.
Но все-таки совсем без драйвера обойтись не получится, поскольку инструкция RDMSR на прикладном уровне возбуждает неизменное исключение. Как же быть?! Intel предоставила крошечную лазейку в виде команды RDPMC читающей текущий счетчик производительности в регистровую EDX:EAX. Текущий — это тот, который до этого был установлен командой WRMSR, запустивший MSR-регистр PerfEvtSel0 или PerfEvtSel1. Однако, по умолчанию, RDMSR с прикладного уровня недоступна и прежде, чем ей удастся воспользоваться необходимо взвести PCE флажок в регистре CR4 (бит 8), модифицировать который можно только из нулевого кольца, зато потом наступает благодать!!!
Подробнее о счетчиках производительности и всем, что с ними связано можно прочитать в разделе "Performance-Monitoring Events and Counters" руководства "Intel Architecture Optimization Reference Manual" или уже упомянутой "библии" системного программиста "Intel Architecture Software Developer's Manual Volume 3: System Programming Guide"

Рисунок 3 бит PCE регистра CR4 управляет доступом к команде RDPMC с прикладного уровня
Таким образом, мыщъх'иная программа состоит из двух частей: крохотного псевдодрайвера и прикладной части.
Драйвер обеспечивает загрузку необходимого кода события в соответствующий MSR-регистр (PerfEvtSel0 или PerfEvtSel1) и запускает счетчик, предварительно "разблокировав" команду RDPMC.
Поскольку, RDPMC способна читать только один счетчик (а нам необходимо отслеживать по меньшей мере два события — промахи кэш памяти кода и данных), драйвер должен обеспечивать IOCTL-интерфейс с прикладным приложением, позволяя ему переключаться с одного счетчика на другой.
Чтобы не переводить понапрасну бумагу, ниже будут приведены только ключевые фрагменты кода, а все остальное читатель без труда допишет и сам. В частности, процедура инициализации драйвера среди прочего должна содержать:
DriverInitialize: ; // процедура инициализации драйвера
…
MOV EAX, CR4
OR EAX, 100h ; // разрешаем доступ к RDPMC с прикладного уровня
MOV CR4, EAX
…
Листинг 3 фрагмент процедуру инициализации драйвера
Следующий код обеспечивает взаимодействие драйвера с прикладной программой через API-функцию DeviceIOControl, передающий в IOCTL-коде номер события, за которым необходимо вести мониторинг. По соображениям наглядности, здесь используется всего лишь один счетчик производительности, управляемый MSR-регистром PerfEvtSel0.
IRP_MJ_DEVICE_CONTROL: ; // процедура обработки IOCTL-запросов
; // настраиваем регистр perfevtsel0 для мониторинга нужных событий
XOR EDX, EDX
MOV EAX, pisl->Parameters.DeviceIoControl.IoControlCode ; //номер события
TEST EAX, EAX ; // если код события равен нулю
JZ wrt ; // то вырубаем счетчик
OR EAX, 10000h ; // делаем счетчик доступным
; // с прикладного уровня
OR EAX, 400000h ; // пускаем счетчик
wrt:
MOV ECX,0x186 ; // выбираем MSR-регистр PERFEVTSEL0
WRMSR
Листинг 4 фрагмент драйвера, отвечающий за выбор нужного события
При деиницилизации драйвера крайне желательно "отобрать" доступ к команде RDPMC с прикладного уровня и остановить все ранее запущенные счетчики производительности, сбросив флажок Enable Counter в MSR-регистрах PerfEvtSel0/PerfEvtSel1 (код, приведенный ниже останавливает только PerfEvtSel0):
DriverUnload: ; // процедура деиницилизации драйвера
…
; // сбрасываем бит pce регистра cr4 для запрета чтения
; // счетчика производительности с пользовательского уровня
MOV EAX, CR4
MOV ECX, 100h
NOT ECX ; // запрещаем доступ к RDPMC с прикладного уровня
AND EAX, ECX
MOV CR4, EAX
; // останавливаем счетчик производительности
XOR EDX, EDX
XOR EAX, EAX
MOV ECX, 186h
WRMSR
…
Листинг 5 фрагмент процедуры деиницилизации драйвера
Прикладная программа первым делом должна загрузить драйвер (пусть для определенности он будет называться 996.SYS), открыв его с помощью функции CreateFile. При этом управление получит процедура инициализации, открывающая доступ к машинной команде RDPMC, но сами счетчики производительности еще не заданы, так что читать, собственно говоря, нечего и незачем.
Нет никакой необходимости писать загрузку драйвера на ассемблере и лучше всего воспользоваться для этой цели языком Си:
// определения необходимых констант
#define PrefCtrl0 0x0000
#define DCU_MISS_OUTSTANDING 0x0048
// дескриптор драйвера 996
static HANDLE _996_handle = INVALID_HANDLE_VALUE;
int _996_init()
{
if (_996_handle == INVALID_HANDLE_VALUE)
{
_996_handle = CreateFile("\\\\.\\996",GENERIC_READ,
FILE_SHARE_READ | FILE_SHARE_WRITE, NULL,
OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL, NULL);
if (_996_handle == INVALID_HANDLE_VALUE) return 0;
} return 1;
}
Листинг 6 прикладная функция, загружающая драйвер в память
Тоже самое относится и к функции, вызывающей DeviceIoControl и передающей ей код интересующего нас события. На языке Си она выглядит гораздо нагляднее:
int _996_select(int xCode, int REG)
{
DWORD x;
if (REG != PrefCtrl0) return 0;
// если программист забыл загрузить драйвер,
// данная функция делает это самостоятельно
if (_996_handle == INVALID_HANDLE_VALUE) _996_init();
// если загрузка драйвера провалилась сваливаем отсюда
if (_996_handle == INVALID_HANDLE_VALUE) return 0;
return DeviceIoControl(_996_handle, xCode, &x,0, &x, 0, &x, 0);
}
Листинг 7 прикладная функция, позволяющая выбирать интересующее нас событие для его мониторинга
Процедура закрытия драйвера должна просто вызывать CloseHandle, а все остальное за нас сделает сам драйвер. Впрочем, драйвер можно и не закрывать. При выходе из приложения операционная система сделает это автоматически.
int _996_exit()
{
if (_996_handle != INVALID_HANDLE_VALUE)
{
CloseHandle(_996_handle);
}
return 1;
}
Листинг 8 прикладная функция выгружающая драйвер из памяти
А вот при снятии показаний со счетчиков производительности без ассемблера уже не обойтись! Для упрощения программирования можно использовать ассемблерные вставки, хоть это и является признаком дурного тона, затрудняющих перенос программы на другие платформы и препятствующей ее компиляции другим компилятором. Правильным решением было бы создание отдельного ассемблерного модуля, но это слишком хлопотно, тем более, что мы пишем не коммерческую программу, а всего лишь демонстрационный макет.
// ИНИЦИЛИЗАЦИЯ ДРАЙВЕРА 996
if (_996_init()==0) return printf("-ERR: 996 driver not loaded!\n");
// ВЫБОР СОБЫТИЯ ДЛЯ МОНИТОРИНГА И ЗАПУСК СЧЕТЧИКА
_996_select(DCU_MISS_OUTSTANDING, PrefCtrl0);
for(;;)
{
__asm
{
mov ecx, PrefCtrl0 ; // читаем регистр PrefCtrl0...
RDPMC ; // ...и помещаем результат в EDX:EAX
mov _edx, edx ; // сохраняем EDX:EAX в...
mov _eax, eax ; // ...одноименных переменных
}
// анализ кол-ва кэш-промахов
// ===========================
…
Sleep(0); ; // отдаем остаток кванта и спим
}
Листинг 9 ключевой фрагмент функции, осуществляющей контроль за кэш-активностью
При снятии показания со счетчиков производительности следует учитывать, что они возвращают количество кэш-промахов с момента запуска счетчика, а не между двумя соседними замерами, так что дельту придется считать самостоятельно. И если эта дельта вдруг превысит некоторое пороговое значение (задаваемое настройками нашей программы), необходимо "притормозить" процессор, чтобы кэш чуть-чуть приостыл. А как это можно сделать? Ведь даже если материнская плата поддерживает изменение тактовой частоты процессора на лету, каждая из них делает это по-разному и у нас получается громоздкая и не универсальная программа.
На самом деле, нет ничего проще! Достаточно просто прекратить отдавать кванты, загрузив процессор "тупой" работой, не требующей обращения к памяти. Например, складывать два регистра в цикле. При условии, что в системе имеются два активных потока, один из которых принадлежит приложению, гоняющему кэш и в хвост и в гриву, а другой поток — гонят цикл в нашей программе, на однопроцессорных материях операционная система будет выделять приложению только 50% машинного времени, следовательно, нагрузка на кэш упадает. А если мы запустим три потока, мотающие такие циклы, кэш-приложение получит только 25% машинного времени! Количество протоков и продолжительность выполнения цикла подбираются экспериментально и для каждого приложения они индивидуальны (а это значит, что для достижения наивысшей производительности придется отслеживать какие приложения запущены и выбирать соответствующий им профиль.муторно конечно, но разгон того стоит):
MOV ECX,-1
cool:
ADD EAX,ECX
DEC ECX
LOOP cool
Листинг 10 цикл, отбирающий процессорные такты у приложения, напрягающего кэш и дающее ему время на остыв
Остается разобраться с "загниванием" байтов в "застоявшейся" кэш-памяти. Ну тут все просто! Хоть мы не можем непосредственно обновить ее содержимое, достаточно просто с некоторой периодичностью (определяемой опять-таки чисто экспериментально) загружать в кэш посторонние данные (ну там мусор какой-нибудь), заставляя приложение заново перечитывать оригинальное содержимое из оперативной памяти. Учитывая, что пропускная способность современных DRAM-контроллеров измеряется гигабайтами в секунду, особого падения производительности это не вызовет, зато позволит разогнать процессор до сумасшедших тактовых частот!
