Шаблоны
Подобно тому, как класс является схемой для создания своих представителей-объектов, шаблон класса в C++ является схемой для образования конкретных представителей-классов шаблона, или шаблонных классов. Шаблоны классов называют иногда параметризованными типами, поскольку действительный тип (класс) создается посредством спецификации конкретных параметров шаблона.
Можно определять также шаблоны функций, с которых мы и начнем.
Явное создание представителя шаблона
В подавляющем большинстве случаев прикладному программисту нужно только сбросить флажок External в диалоге Project Options и больше не беспокоиться о том, как написанные им шаблоны классов будут обрабатываться. Однако, если вы хотите создать, например, динамическую библиотеку на основе шаблона, которая будет содержать код всех его функций-элементов, то для генерирования полного представителя шаблона вам придется воспользоваться директивой template.
Следующий пример включает в себя два исходных файла и один заголовочный, в котором определяется простой шаблон. Главный исходный модуль программы создает два шаблонных объекта для его аргументов int и float, но, поскольку модуль компилируется с директивой #pragma option -Jgx, то никакого кода для представителей шаблона в нем не создается. Вместо этого во втором исходном модуле (компилируемом с ключом -Jgx) явным образом генерируется полный представитель шаблона для аргумента float, а также неявно генерируется представитель для int, так как модуль ссылается на него.
Листинг 10.4. Директива порождения представителя шаблона
//////////////////////////////////////////////////
// Simptmpl.h: Простой шаблон класса.
//
template <class T> class Simple {
protected:
int size;
int current;
T *arr;
public:
Simple(int) ;
~Simple () ;
void Insert(T item)
{ if (current != size) arr[current++] = item; }
T SGet(int) ;
};
template <class T> inline Simple<T>::Simple(int n): size(n),
current (0), arr(new T[n]) {}
template <class T> Simple<T>::~Simple() { delete[] arr; }
template <class T> T SSimple<T>::Get(int idx) { return arr[idx]; }
void Somefunc(int);
/////////////////////////////////////////////////////////
// Instance.cpp: Порождение представителей шаблона. //
#pragma option -Jgx
#include <iostream.h>
#pragma hdrstop
#include <condefs.h>
#include "Simptmpl.h"
USEUNIT("Somefunc.cpp") ;
#pragma argsused
int main(int argc, char* argv[])
{
const int Num = 9;
Simple<int> ia(Num);
Simple<float> fa(Num);
fa.Insert(3.14) ;
cout << "Float In main(): " << fa.Get(O) << endl;
for (int i=0; i<Num; i++)
ia.Insert(i * 2);
cout << "From main(): ";
for (int i=0; i<Num; i++)
cout << ia.Get(i) << " ";
cout << end1;
Somefunc(10);
cin.ignore();
return 0;
}
//////////////////////////////////////////////////////////
// Somefunc.cpp: Функция, использующая шаблон класса. //
#pragma option -Jgd #include <iostream.h>
#pragma hdrstop #include "Simptmpl.h"
//
// Следующая строка генерирует явный представитель шаблона
// для типа float, хотя в данном модуле он не используется:
// template class Simple<float>;
void Somefunc(int n)
{
Simple<int> iArr(n);
for (int i=0; i<n; i++) iArr.Insert (i);
cout << "From Somefunc(): "<< n;
for (int i=0; i<n; i++)
cout<<" "<< iArr.Get(i);
cout <<end1; ;
}
Вывод программы показан на рис. 10.5.
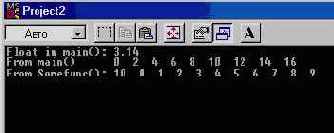
Рис. 10.5 Результат работы программы Instance
Ключевое слово typename
Это ключевое слово может применяться в двух случаях. Во-первых, им можно заменять ключевое слово class в списке параметров шаблона. Такое дополнение сделано в ANSI C++ потому, что ключевое слово class в списке параметров не вполне отражает положение дел;
параметром шаблона может быть любой тип, а не только класс, и стандартный синтаксис может вводить некоторых в заблуждение. Следующие две нотации эквивалентны:
template <class T> class SomeClass {...};
template <typename T> class SomeClass {...};
Во-вторых, typename необходимо, если шаблон определяет некоторые объекты еще не объявленных типов. Рассмотрите такой шаблон функции:
template <class T>
void Func(Т Sargi, typename T::Inner arg2)
{
typename T::Inner tiObj;
// Локальный объект
// типа Т::Inner.
// ...

Нам еще как-то не приходилось говорить, что объявление класса может содержать вложенные объявления других типов, в том числе классов. Например:
class One { public:
class Two {
// Элементы класса Two...
} ;
private:
Two objOfTwo;
// Другие элементы One... }
Сослаться на вложенный тип можно либо через существующий объект, либо с помощью операции разрешения области действия с префиксом имени класса. Очень часто так объявляют перечисления и константы, пример чему вы могли видеть в классе ios, объявляющем перечислимые типы и их константы вида ios::fixed и т. п.
Предполагается, что любые классы, для которых будет вызываться шаблонная функция, должны объявлять тип с именем Inner. Но заранее неизвестно, что это за тип, и в этом случае объекты или аргументы функции, принадлежащие к этому типу, следует объявлять с ключевым словом
typename.
Заключение
В этой главе вы увидели, насколько широкие и мощные возможности предоставляют программисту шаблоны функций и классов. Можно легко объявлять нужные вам классы, создавая представители уже имеющихся шаблонов; существует много больших библиотек, реализующих этот принцип. К их числу относятся, например, библиотека контейнерных классов Борланда и Стандартная библиотека шаблонов ANSI C++ (STL), о которой мы немного расскажем в следующей главе.
Ключи компилятора
Сброшенному флажку External в диалоге Project Options соответствует ключ командной строки компилятора -Jgd, а установленному — -Jgx. Посредством директивы препроцессора #pragma option можно указать ту или иную опцию для конкретного файла. Не следует забывать о том, что компиляция и компоновка программы — два различных этапа ее создания. Компоновщик не знает, что вы задали в диалоге Project Options для компилятора. В любом случае компоновщик не будет включать в исполняемый код повторные определения функций шаблона.
Определение шаблона класса
Определение шаблона класса предполагает:
определение собственно шаблона, синтаксис которого показан выше;
определение функций-элементов шаблона;
определение статических элементов данных.
Определения функций-элементов, расположенные в теле шаблона, ничем не отличаются от определения встроенных функций-элементов обычного класса. Определения функций-элементов, располагаемые вне тела шаблона, имеют такой вид:
template <список параметров шаблона> возвращаемый_тип имя шаблона< параметры_шаблона>::имя_функции(список_параметров) {тело_функции }
Подобным же образом определяются статические элементы данных шаблона класса:
template <список параметров шаблона>
тип имя шаблона
<параметры шаблона>::имя статического элемента[ =значение];
Смысл всех синтаксических элементов определений будет ясен, если рассмотреть пример законченного шаблона класса:
Листинг 10.2. Шаблон класса DataBase
///////////////////////////////////////////////////////
// Deftmpl.h: Пример определения шаблона класса.
//
#ifndef _DEFTMPL_H
#define _DEFTMPL_H
template <class T, int numRec> class DataBase { protected:
const int num.;
bool err;
T *base, *cp;
public:
DataBase (): num(numRec)
{
cp = base = new T[numRec];
err = false;
}
~DataBase () ( delete [] base;
} bool Error () { return err; } T SRec(void) ;
T &Rec(unsigned recno);
};
// Возвращает ссылку на текущую запись
// и переходит к следующей.,
template <class T, int numRec>
Т &DataBase<T, numReO: :Rec (void)
{
if (cp - base == num) { err = true;
return *(cp - 1) ;
}
else
return *cp++;
// Позиционирует указатель и возвращает ссылку
// на текущую запись.
template <class T, int numRec>
T &DataBase<T, numRec>::Rec(unsigned recno)
{
if (recno < (unsigned)num) { err=false;
return *(cp = base+recno);
}
else {
err=true;
return*(cp=base+num-1);
}
}
#endif
//_DEFTMPL_H
Этот шаблон реализует примитивный “поток” или “базу данных”, являющуюся массивом записей, тип которых определяется аргументом шаблона. Класс содержит функции для обращения либо к записи с указанным индексом (Rec (unsigned)), либо к записи, на которую ссылается указатель “базы данных” (Re с (void)). В последнем случае указатель перемещается к следующей записи.
При выходе за пределы массива устанавливается флаг ошибки, и функции Get () возвращают ссылку на последнюю запись.
Параметрами шаблона являются формальный тип записи Т и константа — число записей в массиве.
Функции-элементы шаблона класса, определяемые вне тела шаблона, могут объявляться как встроенные с помощь, ключевого слова inline, подобно функциям-элементам обычных классов. Например, в приведенном выше определении шаблона можно было бы написать:
template <class T,int numRec>
inline T &DataBase<T, numRec>::Rec(void)
{
if (cp-base== num) {err= true/return*(cp-1) ;
} else
return *cp++;
}
Перегрузка шаблонов функций
Шаблоны функций можно перегружать точно так же, как обычные функции. Два шаблона могут иметь одно и то же имя, если их можно различить по списку параметров, например:
// Возвращает больший из двух аргументов.
template <class Т> Т Мах(Т а, Тb) {
return а > b? а : b;
// Возвращает наибольший элемент массива. template <class Т> Т Мах(Т аrr[], size_t size)
(
Т maxVal = arr[0] ;
for(int i=l; i<size; i++) if (arr[i] > maxVal) maxVal = arr[i];
return maxVal;
}
Порождение представителей шаблона
Этот раздел посвящен тому, каким образом C++Builder генерирует шаблонные классы и функции в программах, состоящих из нескольких модулей исходного кода. Несколько модулей проекта могут подключать один и тот же заголовочный файл с шаблоном, и создавать объекты одного и того же шаблонного класса (с одинаковым набором аргументов шаблона). В C++Builder имеются средства, позволяющие избежать дублирования кода в такой ситуации.
Разное
В этом параграфе мы расскажем о некоторых возможностях шаблонов, предусмотренных в стандартном C++, но не реализуемых компилятором C++Builder. Нам кажется, что о них необходимо рассказать, хотя бы для того, чтобы, читая другие книги по C++, вы не пытались осуществить в C++Builder методики, которые на нем осуществить невозможно.
В конце концов, C++Builder не является универсальным инструментом. Он ориентирован на визуальное программирование, а те моменты, о которых мы будем здесь говорить, второстепенны с этой, да и, пожалуй, с любой другой точки зрения.
Если у вас есть Borland C++ 5 или более поздняя версия, и вы хотя бы немного умеете с ним работать, то можете при желании разобрать с его помощью приведенные ниже примеры.
Специализация шаблона класса
Подобно шаблону функции, шаблон класса может быть специализирован для специфического набора его аргументов. Для этого нужно написать явные реализации тех или иных методов шаблона для конкретных типов. Вот, например, шаблон, который генерирует класс массива объектов, в том числе символьных строк, для которых отдельно реализуется функция добавления в массив и деструктор:
#include <iostream.h>
#include <string.h>
const int DefSize = 4;
template <class T> Glass MyArray { protected:
int size;
int current;
T *arr;
public:
MyArray (int n = DefSize) { size = n;
current = 0;
arr = new T[size];
}
~MyArray ();
void Insert(const T Sitem);
T &Get(int idx) { return arr[idx]; } };
// Общий шаблон Insert:
template <class T> void MyArray<T>::Insert(const T Sitem)
{
if (current == size) return;
arr[current++] = item;
}
// Специализированная Insert для параметра char*:
void MyArray<char*>::Insert(char* const Sitem)
{
if (current == size) return;
arr[current] = new char[strlen(item) + 1];
strcpy(arr[current++], item);
}
// Общий деструктор:
template <class T>
MyArray<T>::-MyArray () ( delete[] arr; }
// Специализированный деструктор:
MyArray<char*>::-MyArray() (
for (int i=0; i<size; i++)
delete [ ] arr[i];
delete [ ] arr;
}
А вот главная функция, тестирующая шаблон для “стандартного” типа int и для “специального” типа строк (т. е. char*):
int main(void)
{
// Создание, заполнениеи вывод MyArray<int>.
MyArray<int> *iArr;
iArr = new MyArray<int>;
int i;
for (i=0; i<DefSize; i++) iArr->Insert (i);
cout << "Integers: ";
for (i=0; KDefSize; i++)
cout << " " << iArr->Get(i);
cout<< end1<< end1;
delete iArr; // Уничтожение объекта.
// Создание, заполнение и вывод MyArray<char*>.
MyArray<char*> *sArr;
sArr = new MyArray<char*>;
for (i=0; KDefSize; i++) sArr->Insert("String!");
cout << "Strings: ";
for (i=0; KDefSize; i++)
cout << " " << sArr->Get(i) ;
cout << end1;
delete sArr; // Уничтожение объекта.
return 0;
}
Полная специализация шаблона
Можно также полностью переопределить шаблон класса для какого-то конкретного типа аргумента. Это значит, что после определения общего шаблона нужно определить специализированный шаблон класса и предусмотреть переопределения всех его элементов-функций и статических элементов данных. Ниже приводится вариант предыдущего примера, использующий такую методику:
#include <iostream.h>
#include <string.h>
const int DefSize = 4;
// Общий шаблон:
template <class T> class MyArray { protected:
int size;
int current;
T *arr;
public:
MyArray(int n = DefSize) { size = n;
current = 0;
arr = new T[size];
}
~MyArray() { delete[] arr; }
void Insert(const T &item) {
if (current == size) return;
arr[current++] = item;
}
T &Get(int idx) { return arr[idx]; } } ;
// Специализированный шаблон для char*:
class MyArray<char*> { protected:
int size;
int current; char **arr;
public:
MyArray(int n = DefSize) { size = n;
current = 0;
arr = new char*[size];
} ~MyArray() ;
void Insert(char* const &item) { if (current == size) return;
arr[current] = new char[strlen(item) + 1];
strcpy(arr[current++], item);
} char* &Get(int idx) { return arr[idx]; }
};
// Деструктор специализированного шаблона:
MyArray<char*>::~MyArray() {
for (int i=0; i<size; i++) delete [ ] arr[i] ;
delete[] arr;
}
Заметьте, что все функции- элементы общего шаблона определены теперь как встроенные, а в специализированном только деструктор определен вне тела шаблона (его нельзя объявить как встроенный, поскольку он содержит оператор цикла). В общем, полное переопределение шаблона целесообразно в том случае, когда необходима специализация большинства его элементов-функций. Главная функция ничем не отличается от функции предыдущего примера.
Функции, дружественные шаблону
В качестве “друзей” класса чаще всего объявляют различные функции-операции, в которых участвуют объекты класса. Типичным примером может служить операция передачи объекта в поток. Для шаблона класса можно определить шаблон дружественной функции (не обязательно, конечно, операции). Такой шаблон будет порождать отдельную дружественную функцию для каждого генерируемого шаблонного класса. Вот пример шаблона дружественной функции (это модификация первого примера параграфа):
#include <iostream.h>
#include <string.h>
const int DefSize = 4;
template <class T> class MyArray { protected:
int size;
int current;
T *arr;
public: MyArray(int n = DefSize) { size = n; current = 0;
arr = new T[size];
} ~MyArray();
void Insert(const T&);
T &Get(int idx) { return arr[idx]; }
friend ostream &operator“(ostream&, const MyArray<T>&);
};
// Шаблон дружественной функции-операции передачи объекта // в поток:
template <class T>
ostream &operator<<(ostream &os, const MyArray<T>&ma)
{
for (int i=0; i<ma.current; i++) os << " (" << ma.arr[i]<< "}";
return os;
}
//
// Здесь находятся общие и специализированные
// функции-элементы... //
Определенный таким образом шаблон функции-операции реализует передачу в поток всего объекта, в противоположность предыдущим примерам, где объекты шаблонных классов выводились поэлементно. Главная функция:
int main(void)
{
MyArray<int> *iArr;
iArr = new MyArray<int>;
int i;
for (i=0; KDefSize; i++) iArr->Insert (i) ;
// Вывод объекта MyArray<int>:
cout << "Integers: " << *iArr<< endl;
cout << endl;
delete iArr;
MyArray<char*> *sArr;
sArr = new MyArray<char*>;
for (i=0; i<DefSize; i++) sArr->Insert("String!");
// Вывод объекта MyArray<char*>:
cout << "Strings: "<< *sArr << endl;
delete sArr;
return 0;
}
Результат работы программы показан на рис. 10.3.

Рис. 10.3 Пример с шаблоном
дружественной
функции-операции
Шаблоны функций
Синтаксис определения шаблона функции имеет вид:
template <список формальных типов>возвращаемый_тип имя_функции(список параметров) {
тело функции }
Список_формальных_типов состоит из спецификаций вида class формалъный_тип, разделенных запятыми. Формальный тип может обозначаться любым идентификатором, аналогично формальному параметру функции.
Список _параметров функции должен включать в себя параметры типов, перечисленных в списке формальных _типов, и еще, возможно, какие-то другие. Возвращаемый_тип также может быть одним из формальных типов. Например:
template <class T> void Func1 (Та, Т b) { ... }
template <class T> T Func2(Т a, int b) { ... }
template <class Tl, class T2> long Func3(Tl a, T2 b) { ... }
Как видите, определение шаблона функции отличается от обычной функции только наличием конструкции template <список_формальных_типов> в заголовке.
В качестве примера шаблонов функций можно привести определение функций min () и max () из заголовочного файла sdlib.h. Определение это сводится к следующему:
template <class T> inline const Т &min(const Т&t1, const T&t2)
if (t1 < t2)
return tl;
else
return t2;
}
template <class T>
inline const T &max(const T &tl, const T &t2)
{
if (t1 > t2) return t1;
else
return t2;
}
Эти функции можно вызывать с аргументами любого типа (класса), в котором определены операции “больше-меньше”.
Когда компилятор встречает вызов функции шаблона, он автоматически порождает представитель шаблона, подставляя вместо формального типа конкретный тип аргумента, с которым вызывается функция.
Шаблоны функций размещают чаще всего в заголовочных файлах, подобно определениям макросов и inline-функций.
Шаблоны классов
Шаблон класса является обобщенным определением некоторого семейства классов, имеющих схожую структуру, но различных в смысле используемых типов или констант. Синтаксис шаблона класса следующий:
template <список параметров шаблона> class имя шаблона {тело_класса };
В списке_параметров_шаблона .могут присутствовать элементы двух видов:
спецификации формальных констант, состоящие из имени некоторого типа с последующим идентификатором;
спецификации формальных типов, состоящие из ключевого слова class, за которым следует идентификатор; они аналогичны параметрам шаблона функции.
Создание представителей шаблона
Чтобы создать из шаблона представитель конкретного класса, нужно конструировать объект, указав для его типа имя шаблона с набором конкретных аргументов (типов и констант). Каждый формальный тип в списке параметров шаблона нужно заменить на имя действительного типа. Каждая формальная константа заменяется на константу указанного в шаблоне типа:
// Шаблон класса. template <ciass T, int О class TmplClass { ... };
// Создание представителей шаблонных классов.
TmplClass<long, 100> IClassObj;
TmplClass<float, 40> *fClassPtr;
fClassPtr = new TmplClass<float, 40>;
После того, как представитель шаблонного класса создан, с ним можно обращаться точно так же, как с любым объектом, принадлежащим к обыч-
ному классу. Ниже показан пример программы, использующей определение шаблона из листинга 10.2.
Листинг 10.3. Создание и использование представителя шаблонного класса
///////////////////////////////////////////////
// Usetmpl.cpp: Использование шаблона класса. //
#include <iostream.h>
#pragma hdrstop
#include <condefs.h>
#include "Deftmpl.h"
// Включить определение шаблона.
// Класс записей, для которого будет создан шаблонный класс. class Record {
char str[41] ;
public:
Record(void) { str[0] = 0; }
void Set(const char *s)
{ strncpy(str, s, 40);}
char *Get(void)
{ return str; } };
#pragma argsused
int main(int argc, char* argv[])
{
const int NumRec = 4;
DataBase<Record, NumRec> db; // Объявление объекта
// с 4-мя записями.
// Инициализация массива.
db.RecO .Set("First string.");
db.Rec().Set("Second string.");
db.RecO .Set("Third string.");
db.Rec().Set("Fourth string.");
cout.setf(ios::boolalpha);
// Чтение с попыткой выхода за пределы массива.
db.Rec(O); // Позиционирование на 0.
for (int i=0; i<=NumRec; i++) {
cout << db.RecO .Get() << " Error: ";
cout << db.Error() << endl;
} cout << endl;
// Чтение с прямым указанием индекса.
for (int i=NumRec-l; i>-l; i--) {
cout << db.Rec(i).Get() << " Error: ";
cout << db.Error() << endl;
}
return 0;
}
Вывод программы показан на рис. 10.2.
В начале файла программы находится определение класса Record, который используется как аргумент шаблона DataBase. Это класс строк с конструктором по умолчанию и операциями чтения-записи содержимого строки.
Программа создает представитель шаблонного класса DataBase< Record, 4> и выполняет над ним различные действия — запись строк в “поток”, позиционирование, чтение.
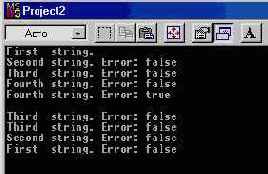
Рис. 10.2 Программа UsetmpI
Когда при обработке исходного файла компилятору встречается создание объекта на основе некоторого шаблона класса, он прежде всего генерирует представитель шаблона, или шаблонный класс, как мы его назвали. По существу при этом генерируется и компилируется код всех функций-элементов шаблона для данного набора его аргументов (и код некоторых вспомогательных функций). После этого компилятор может конструировать объект шаблонного класса, вызывать нужные функции-элементы объекта и т. д.
Если создается шаблонный объект, аргументы которого совпадают с аргументами объекта, ранее созданного в текущем модуле компиляции, то новый представитель шаблона не генерируется. Данный шаблонный класс уже существует, остается только конструировать объект.
Для удобства работы с шаблонными классами можно воспользоваться определением typedef, например:
template<class T> TmplClass { ... };
typedef TmplClass<int> IClass;
IClass iCIassObj; IClass *iCiassPtr; iCIassPtr = new IClass;
Специализация шаблона функции
Несколько напоминает перегрузку шаблонов ситуация, когда определяется обычная функция, имя которой совпадает с именем шаблона и список параметров которой соответствует шаблону с некоторым специфическим набором фактических типов. Такую функцию называют специализированной функцией шаблона. Этот прием применяют, когда для некоторого типа или набора типов общий шаблон работать не будет.
Допустим, мы хотим, чтобы шаблон Мах()из последнего примера порождал функцию для двух аргументов-строк, которая возвращала бы большую из них (в смысле алфавитного порядка). Функция Мах (char*, char*), порожденная из первого шаблона, сравнивала бы адреса строк вместо их содержимого. Поэтому нужно определить отдельную функцию Мах (char*, char*):
char *Max(char *a, char *b) {
return strcmp(a, b) > 0? а : b;
}
Когда компилятор встречает вызов какой-то функции, для его разрешения он следует такому алгоритму:
Сначала ищется обычная функция с соответствующими параметрами.
Если таковой не найдено, компилятор ищет шаблон, из которого можно было бы генерировать функцию с точным соответствием параметров.
Если этого сделать невозможно, компилятор вновь рассматривает обычные функции на предмет возможных преобразований типа параметров.
Ниже приводится полный пример, иллюстрирующий различные аспекты перегрузки и специализации шаблонов.
Листинг 10.1. Перегрузка и специализация шаблона
////////////////////////////////////////////////////////
// Functemp.cpp: Шаблоны функций.
//
#include <string.h>
#include <iostream.h>
#pragma hdrstop
#include <condefs.h>
// Возвращает больший из двух аргументов.
template <class Т> Т Мах(Т а, Т b) {
return a > b? a : b;
}
// Возвращает наибольший элемент массива.
template <class Т> Т Мах(Т аrr[], size_t size) {
Т maxVal = arr[0] ;
for(unsigned i=l; i<size; i++)
if (arr[i] > maxVal)
maxVal = arr[i] ;
return maxVal;
}
// Возвращает большую из двух строк.
char *Max(char *a, char *b)
{
return strcmp(a, b) > 0? а : b;
}
// Вызывается для целочисленных аргументов // различающихся типов. long Max(long a, long b)
{
return Max<long>(a, b);
}
#pragma argsused int main(int argc, char* argv[])
{
int il = 11, i2 = 22;
float fl = 1.11, f2 = 22.2;
char str1[] = "First string.";
char str2[] = "Second string.";
char с = 33;
cout << "Max int: " << Max(il, i2) << endl;
cout<< "Max float: " “ Max(fl, f2) << endl;
cout << "Max element: "<< Max(strl, strlen(strl)) << endl;
cout << "Max string: " << Max(strl, str2) << endl;
cout << "Max(int,char): " << Max(i1, c) << endl;
return 0;
}
Последнее определение—Max (long, long) — требует некоторых пояснений. Эта специализированная функция вызывает явным образом функцию шаблона для сравнения двух аргументов фактического типа long. Но какой в этом смысл?
Если не определить такую функцию, компилятор вообще не сможет вызвать, например, Мах (int, char), как в последнем операторе вывода. (Подобные сравнения являются на самом деле “признаком дурного тона”.) Имеется только шаблон, два параметра которого имеют один и тот же тип, а как говорилось выше, компилятор использует шаблон только в том случае, если можно получить точное соответствие параметров типам аргументов в вызове. Однако благодаря определению специализированной функции компилятор может разрешить вызов, преобразовав char в long.
На рисунке показан результат работы программы.
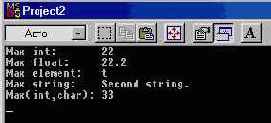
Рис. 10.1 Программа Functemp
Установки проекта и ключи компилятора
В диалоге Project Options на странице C++ имеется флажок Templates: External (рис. 10.4). По умолчанию он сброшен, что означает оптимальное, или “интеллигентное”, порождение представителей шаблонов классов и функций.
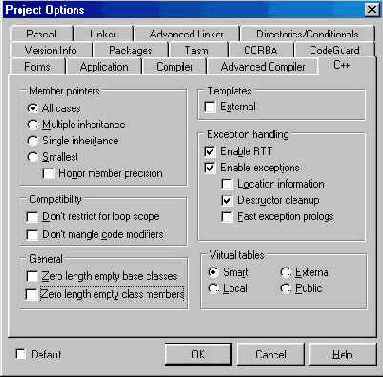
Рис. 10.4 Страница C++ диалога Project Options
При сброшенном флажке External компилятор порождает глобальные представители шаблонов для всех модулей, где создаются объекты шаблонных классов (или вызываются шаблонные функции). Это возможно только в том случае, если компилятор при обработке модуля “видит” все определение шаблона, со всеми его функциями-элементами. Однако объектный код не обязательно генерируется для всех шаблонных методов (определенных как не-встроенные). По умолчанию код генерируется для методов:
действительно вызываемых в модуле;
виртуальных;
всех методов явным образом генерированного представителя шаблона класса.
Что означает последний пункт, будет рассказано чуть ниже.
После этого компоновщик ilink32.exe анализирует код объектных файлов и помещает в исполняемый файл только один экземпляр функции для каждой комбинации шаблон/аргументы.
Если же флажок External будет установлен, то компилятор вообще не будет генерировать никакого кода для не-встроенных функций класса, а будет рассматривать их вызовы как внешние ссылки. Такой вариант может иметь смысл, если, допустим, вы используете в своем проекте библиотеку, в заголовочных файлах которой определяются некоторые шаблоны и в которой уже имеется компилированный код для всех имеющих смысл представителей шаблонов.
Алгоритмы
Алгоритмы стандартной библиотеки выполняют разные распространенные действия на наборах данных, представленных стандартными контейнерами. Среди этих действий можно назвать сортировку, поиск, замену и т. д. Ниже мы вкратце опишем имеющиеся в библиотеке алгоритмы, не вдаваясь в подробности и не приводя развернутых примеров. Применение стандартных алгоритмов достаточно очевидно и, как правило, не вызывает никаких затруднений.
Чтобы можно было вызывать эти алгоритмы, нужно включить в программу заголовок algorithm:
#include <algorithm>
using namespace std;
(Не забывайте указывать пространство имен std, когда пользуетесь новой нотацией включаемых файлов!)
Некоторые алгоритмы вы уже видели (например, find ()), так что здесь мы показываем в основном те, с которыми вы еще не встречались.
Библиотека стандартных шаблонов
До сравнительно недавнего времени в языке C++ не было других стандартных средств программирования, кроме старой библиотеки стандартных функций С, которая совершенно не использовала мощных нововведений, таких, как классы, шаблоны, inline-функции и исключения. Библиотека стандартных шаблонов (Standard Template Library), разработанная в HP Laboratories, явилась в свое время весьма удачным шагом в решении проблемы стандартной библиотеки ANSI C++, в которую она теперь и входит.
Это весьма обширное собрание структур данных и алгоритмов общего назначения, которое позволяет решать самые различные задачи обработки наборов данных.
Битовые множества
Битовое множество представляет собой контейнер, в котором могут храниться битовые последовательности фиксированной длины. Можно сказать, что оно служит представлением подмножеств фиксированного множества (в математическом смысле), каждому элементу которого соответствует один бит в определенной позиции. Единичный бит означает, что элемент принадлежит подмножеству, нулевой — что он не входит в данное подмножество. Подобным образом организованы множества языка Pascal.
Биты в bitset плотно упакованы, так что информация хранится очень экономно. Однако минимальный физический размер bitset равен 4 байтам — размеру int.
Создание битовых множеств
При создании битового множества указывается его размер (как аргумент шаблона). Можно инициализировать bitset строкой, состоящей из нулей и единиц:
bitset<32> bset1;
bitset<8> bset2(string ( "01011011"));

Вторая форма конструктора объявлена как explicit, с аргументом типа string, поэтому приходится делать явное преобразование литеральной строки в стандартную.
Действия над bitset
У класса bitset нет итераторов, и обращение к его элементам осуществляется по индексу.
Порядок следования элементов в bitset с точки зрения индексации является обратным расположению нулей и единиц в инициализирующей строке. (Это соответствует семантике двоичных чисел — слева стоит самый старший бит, которому обычно приписывают наибольший номер.)
Функция-элемент test() позволяет проверить состояние бита с указанным индексом. Функция апу() возвращает true, если хотя бы один из битов множества установлен.
Функции set () и reset () служат соответственно для установки и сброса битов множества. При указании индекса в качестве аргумента функция устанавливает/сбрасывает соответствующий бит; при вызове функции без аргумента устанавливаются/сбрасываются все биты множества.
Функция flip () инвертирует состояние указанного бита или всех битов множества.
К битовым множествам можно применять обычные логические поразрядные операции и сдвиги (~, &, |, ^, <<, >>).
Для битовых множеств определена операция передачи в поток (<<).
Вот небольшой пример, иллюстрирующий возможности битовых множеств:
#include <iostream>
#include <bitset>
#pragma hdrstop
#include <condefs.h>
using namespace std;
int main() {
bitset<8> bsetl, bset3;
bitset<8> bset2(string ("01011011"));
bsetl.set (0);
bsetl [7] = 1;
cout<< "First bitset : "<< 'bsetl<< endl;
cout << "Second bitset: " << bset2 << endl;
bsetl.flip();
cout<< "Flip first : " << bsetl << endl;
bset3 = bsetl ^ bset2;
cout << "First^second : " << bset3 << end1;
bset3 <<= 4;
cout << "Shifted by 4:" << bset3 << end1;
return 0;
}
Этот код выводит:
First bitset : 10000001
Second bitset: 01011011
Flip first : 01111110
First^second : 00100101
Shifted by 4 : 01010000
Функции и функциональные объекты
Некоторые алгоритмы стандартной библиотеки C++ требуют функций в качестве параметров. Простейший пример — алгоритм for each (), который вызывает переданную ему функцию для каждого элемента контейнера. В этом разделе мы рассмотрим вопросы, связанные с функциональными параметрами алгоритмов.
Функции и предикаты
Иногда нужно выполнить какое-то действие для каждого элемента контейнера. Упомянутый выше алгоритм for_each() позволяет сделать именно это. Функция, выполняющая необходимое действие для отдельного элемента, передается как третий аргумент алгоритма. Первые два задают диапазон. Вот пример:
void Square(int arg) { return arg * arg; }
int main() {
vector<int> iVect;
for_each(iVect.begin (), iVect.end(), Square);
}
Двухместные функции принимают два параметра. Часто они применяются к элементам различных контейнеров. Например, имеется два списка, и нужно что-то сделать с элементом первого списка в зависимости от значения соответствующего ему элемента во втором. Это делается с помощью алгоритма transform (), одна из форм которого имеет вид
template <class Inputlteratorl, class Inputlterator2,
class Outputlterator, class Binary0peration>_
Outputlterator transform(Inputlteratorl firsti,
Inputlteratorl lasti,
Inputlterator2 first2,
Outputlterator result,
BinaryOperation binary_func);
Первые два параметра задают диапазон первого контейнера. Параметр first2 указывает начало второго контейнера. Контейнер, куда будет записан результат, начинается с result. Последний параметр — указатель на двухместную функцию преобразования.
Особо можно выделить функции- предикаты. Предикат — это функция, возвращающая булево значение. Они используются с алгоритмами типа find_if () , который находит в указанном диапазоне значение, для которого предикат истинен:
template <class Inputlterator, class Predicate>
Inputlterator find if(Inputlterator first,
Inputlterator last,
Predicate pred);
Функциональные объекты
Функциональный объект — это представитель класса, в котором определена операция вызова (скобки). Существуют различные ситуации, когда желательно передавать алгоритмам не функции, а функциональные объекты. Иногда это позволяет применить готовый функциональный объект стандартной библиотеки вместо новой функции; иногда — улучшить производительность благодаря генерированию встроенного кода. Кроме того, операция вызова может иметь доступ к информации, которая хранится в объекте — функциональный объект, в отличие от функции, обладает “памятью”.
В библиотеке шаблонов имеется ряд стандартных функциональных объектов, предназначенных для передачи алгоритмам в качестве параметра, задающего конкретную операцию. Вот они:
| Функциональный объект |
Операция |
|
Арифметические |
|
| plus | сложение х + у |
| minus | .вычитание х - у |
| multiplies | умножение х * у |
| divides | деление х / у |
| modulus | остаток х % у |
| negate | смена .знака -х |
|
Отношения |
|
| equal to | равенство == |
| not equal to | неравенство != |
| greater | больше > |
| less | меньше < |
| greater equal | больше или равно >= |
| less equal | меньше или равно <= |
|
Логические |
|
| logical and | логическое И && |
| logical or | логическое ИЛИ | | |
| logical not | логическое отрицание ! |
transform(vec.begin(), vec.endf), vec.begin(),
negate<int> ());
меняет знак всех элементов вектора vec.
Можно привести примеры более сложных функциональных объектов с “памятью”, которые хранят между вызовами информацию о своем текущем состоянии. Определяемые пользователем функциональные объекты часто производятся от шаблонов классов unary_function и binary_function.
Типичным примером функциональнь1х объектов, сохраняющих свое состояние, являются различные генераторы, как, например, генератор случайных чисел.
Вот программа, в которой реализуется совсем простой функциональный объект — генератор чисел Фибоначчи:
///////////////////////////////////////////////////
// FuncObj.cpp: Генератор чисел Фибоначчи.
//
#include <iostream>
#include <algorithm>
#include <vector>
#pragma hdrstop #include <condefs.h>
using namespace std;
class Fibo { // Класс функционального объекта.
int iCur, iNext;
public:
Fibo() { iNext = iCur =1; } // Инициализация состояния.
int operator ()() { // Операция вызова; возвращает
int temp = iCur; // следующий член ряда.
iCur = iNext; iNext = iCur + temp;
return temp;
} };
int main () {
//
// Сначала проверим вручную, как работает класс.
// Fibo fObj ;
cout << "Generated sequence of 16 numbers:" << endl;
for (int i=0; i<15; i++) cout << fObj () << ", ";
cout << f0bj() “ endl;
//
// Теперь генерируем вектор с помощью
// стандартного алгоритма.
//
vector<int> iVec(16);
generate (iVec .begin (), iVec.end(), Fibo());
cout << endl<< "Vector initialized by generate () algorithm:"<< endl;
copy (iVec .begin (), iVec.end(),ostream_iterator<int> (cout, " "));
return 0;
}
Программа выводит:
Generated sequence of 16 numbers:
1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987
Vector initialized by generate() algorithm:
1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987
Объекты-связки
Связка создает из двухместного функционального объекта одноместный функциональный объект, фиксируя значение одного из аргументов. В библиотеке шаблонов имеется два объекта-связки, bindlst и bind2nd. Они предназначены для фиксации соответственно первого или второго аргумента.
Следующий фрагмент кода подсчитывает число элементов в списке со значениями, большими 10:
int count = 0;
count_if (aList .begin ()., alist.end(),
bind2nd(greater<int>(), 10), count);
cout<< "Number of elements greater than 10 = " << count<< endl;
Здесь связка bind2nd применяется к функциональному объекту greater, задавая его второй аргумент равным 10 (если применить связку bindlst, то будут подсчитаны элементы, меньшие 10.
Негаторы
Негатор создает из функционального объекта другой объект с прямо противоположным действием, т. е. служит выражением отрицания. В библиотеке есть два негатора, noti и not2, применяемые соответственно к одноместным и двухместным функциональным объектам. Например,
noti(bind2nd(greater<int>(), 10))
означает “не больше 10”. Конечно, такое отношение можно записать и без негатора (имеется функциональный объект less_equal), но все равно негаторы часто оказываются полезны.
Функции строк
Класс string (точнее, basic_string) имеет богатый набор функций, выполняющих обработку строк. Мы расскажем только о некоторых.
Присваивание и присоединение
Функции assign () и append () делают в общем-то то же, что и операции присваивания и сложения, однако обладают большими возможностями благодаря дополнительным параметрам. Можно, например, скопировать из одной строки в другую определенное количество символов, начиная с некоторой позиции:
string si("Some String already exists."), s2;
s2.assign (si, 5, 6); // Скопирует только слово "String".
Функции assign () и append () имеют аналогичные перегруженные формы и различаются только тем, что первая полностью заменяет текущее содержимое строки новым текстом, а вторая дописывает тот же текст в конец строки. Приведем все имеющиеся формы этих функций, чтобы дать читателю представление о том, что там вообще есть (возвращаемый тип пропущен — все они возвращают basic_string&):
append (const basic strings s);
append (const. basic_string& s, size type pos, size_type npos);
append (const charT* s, size type n);
append (const charT* s);
append (size_type n, charT с );
append (Inputlterator first, Inputlterator last);
assign (const basic strings s);
assign (const basic_string& s,
size__type pos, size_type n);
assign (const charT* s, size type n);
assign (const charT* s);
assign (size_type n, charT с);
assign (Inputlterator first, Inputlterator last);
Вставка и удаление
Функции insert () и erase () производят соответственно вставку указанного текста в заданное место строки и удаление фрагмента строки. Третья функция, replace (), является их комбинацией: делается вставка, а затем часть старого содержимого строки удаляется.
Приведем всего один пример, простейший:
string s1 ("First string.");
string s2(" and second");
si.insert(s1.find(' '),s2);
В данном случае insert () вставляет содержимое второй строки в первую перед найденным в ней пробелом. Следующий оператор удалит только что вставленную строку:
sl.erase(sl.find(' '), 11);
Есть восемь перегруженных вариантов функции insert () и десять вариантов replace () . Для erase () , правда, имеются всего три формы. Все это при желании читатель может найти в оперативной справке С++Вuilder.
Поиск в строках
Функции семейства поиска очень разнообразны. Различные разновидности их еще и перегружены, так что общее число доходит до двух десятков. Функции семейства могут выполнять следующие операции.
Функция find () наиболее проста; она ищет первое вхождение строки, строки С или одиночного символа, начиная с указанного места, по умолчанию от начала, и возвращает позицию найденного фрагмента:
int i = s1.find("and");
Если указанный элемент текста не найден, функции поиска возвращают -1. Правда, возвращаемое ими значение имеет, по-видимому, беззнаковый тип (у меня не было желания в этом разбираться); во всяком случае, если это значение выводить на терминал без приведений, печатается беззнаковый эквивалент минус единицы.
Функция find_first_of () ищет первое вхождение в строку символа из указанного набора. По умолчанию поиск начинается от начала.
Функция find first not of() ищет первое вхождение символа, не входящего в указанный набор.
Функции find_last_of() и find_last_not_of() работают аналогично двум предыдущим функциям, но поиск начинается по умолчанию с конца строки и идет в направлении к ее началу.
Вот простейший пример подобного поиска:
string s("13:30:00 11/03/2000");
int k=0;
k=s.find_first_of(" :/",k) ;
Обычно эти функции используются для поиска разделителей или пропуска незначащих символов при синтаксическом разборе строк.
Преобразование в строки С
Две эквивалентных функции c_str () и data () возвращают константный указатель на строку, ограниченную нулем. Получив такой указатель и, возможно, скопировав содержимое стандартной строки средствами библиотеки С, можно затем работать со строкой, так сказать, в стиле языка С.
Можно также сразу скопировать содержимое строки (или его часть, что бывает удобно) в символьный буфер функцией copy ():
char buf[40];
string s = "abcdefghijklmnopqrstuvwxyz";
s.copy(buf 10 3);
buf[10]='\0';
Этот фрагмент копирует 10 символов из строки s в символьный буфер, начиная с 3-й позиции (т. е. с буквы d). Функция copy (), правда, не записывает в буфер конечный нуль, так что его приходится добавлять вручную.
Заключение
В этой главе вы познакомились с библиотекой стандартных шаблонов, то есть с контейнерами, строками и всем, что с ними связано — итераторами, функциональными объектами и т. п. Сила стандартных контейнеров в том, что они представляют собой готовые динамические структуры данных, которые сами следят за выделением и удалением памяти под свои данные. Программисту остается только грамотно написать базовый класс для хранящихся в контейнере объектов, снабдив его необходимыми конструкторами, деструкторами и перегруженными операциями. Все остальное сделает контейнер, обеспечив поддержание корректности структуры данных в процессе работы программы.
Характеристики строк
Как и контейнеры, строки характеризуются своим размером и вместимостью. Вот сводка функций-элементов, позволяющих манипулировать различными характеристиками строк. Они аналогичны соответствующим функциям контейнеров:
| Функция | Возвращаемый тип | Описание | |||
| size () | size type | Возвращает текущий размер строки. | |||
| length() | size type | Длина строки (то же, что и size). | |||
| capasity() | size type | Возвращает вместимость строки. | |||
| max size() | size type | Возвращает максимально возможный размер. | |||
| resize(n) | void | Изменение размера (может урезать строку). | |||
| reserve(n) | void | Резервирование по крайней мере n символов. | |||
| empty () | bool | Возвращает true, если строка пуста. |
Функции resize () и reserve () могут выбрасывать исключение length_error, если запрашиваемый размер больше максимально возможного (он обычно определяется размером наибольшего свободного блока памяти).
Итераторы
Итераторы, как было замечено выше, являются центральным механизмом, обеспечивающим работу с данными контейнеров. Они являются аналогом указателей и делают возможным циклический перебор всех элементов контейнера. Существуют разные виды итераторов, поскольку различные алгоритмы по-разному обращаются к данным. Каждый класс контейнера может порождать итераторы, необходимые для работы адекватных ему алгоритмов.
Подобно указателю, итератор может ссылаться на единственный элемент данных; пара итераторов может задавать определенный диапазон контейнера; итератор может иметь т. н. запредельное значение, аналогичное NULL и означающее, что его нельзя разыменовывать.
Следует упомянуть, что при вызове различных алгоритмов для диапазона, заданного парой итераторов, второй из них соответствует не последнему значению итератора в диапазоне, а следующему за ним.
Основными операциями над итераторами- являются, как и в случае указателей, разыменование и инкремент. Если итератор i после конечного ряда приращений может стать равным итератору j, то говорят, что итератор j достижим из i. Если к итератору, достигшему верхней границы диапазона, применить операцию инкремента, он примет запредельное значение.
Сделав такие предварительные замечания, мы перейдем теперь к конкретному изучению итераторов библиотеки стандартных шаблонов.
Типы итераторов
Существует пять основных форм итераторов:
Входной итератор обеспечивает доступ к контейнеру только для чтения в поступательном направлении (т. е. к итератору применима операция инкремента).
Выходной итератор обеспечивает доступ только для записи, также в поступательном направлении.
Поступательный итератор предоставляет доступ для чтения-записи в поступательном направлении.
Двунаправленный итератор допускает чтение и запись как в поступательном, так и реверсивном направлениях (к нему применимы как инкремент, так и декремент).
Итератор произвольного доступа предоставляет прямой доступ к данным для чтения-записи.
Итераторы, стоящие в этом списке ниже, выводятся из тех, что находятся выше. Это едва ли не единственный пример классовой иерархии в 8TL.
В следующей таблице показано, какими контейнерами стандартной библиотеки генерируются те ли иные итераторы.
Таблица 10.2. Итераторы, генерируемые стандартной библиотекой
| Форма итератора | Контейнеры |
| входной итератор | istream iterator |
| выходной итератор | ostream iterator |
| двунаправленный итератор | List set и multiset map и multimap |
| итератор произвольного доступа |
обычные указатели vector deque |
Указатели как итераторы
Чтобы продемонстрировать, как применяются итераторы, мы рассмотрим простейший вид итератора — обычный указатель. Следующая программа вызывает стандартный алгоритм find() для поиска значения в обычном массиве.
#include <algorithm>
#include <iostream>
using namespace std;
#define SIZE 50 int iArr[SIZE] ;
int main() {
iArr[30] = 33;
int *ip = find(iArr, iArr + SIZE, 33);
if (ip != iArr + SIZE)
cout<< "Value "<< *ip<< " found at position "<< (ip - iArr)<< endl;
else
cout << "Value not found."<< endl;
return 0;
}
Прежде всего обратите внимание, что программа, применяющая стандартную библиотеку C++, должна специфицировать директивой using namespace пространство имен std.
В примере объявляется “контейнер” — обычный массив длиной в 50 элементов, одному из его элементов присваивается значение 33 и вызывается алгоритм find () для поиска этого значения.
Алгоритму find () передаются три аргумента. Два из них — итераторы, задающие диапазон поиска. Первый из них в данном случае указывает на начальный элемент массива, второй имеет запредельное значение iArr + SIZE, т. е. смещен на один элемент за верхнюю границу массива. Третий аргумент задает искомое значение.
Если find () находит его в заданном диапазоне, алгоритм возвращает соответствующий ему итератор; если нет, возвращается запредельное значение.
Итераторы контейнеров
Итераторы, генерируемые классами контейнеров, используются точно таким же образом, как указатели в показанном выше примере, но для получения граничных значений итератора вь1зываются обычно функции вроде begin () или end () конкретного контейнерного объекта. Вот совершенно аналогичный предыдущему пример для контейнера-вектора:
#include <algorithm>
#include <vector>
#include <iostream>
using namespace std;
#define SIZE 50 vector<int> iVect(SIZE);
int main() {
iVect[30] = 33;
vector<int>::iterator ii =
find (iVect. begin (), iVect.endO, 33);
if (ii != iVect.endO)
cout << "Value "<< *ii<< " found at position "
<< distance(iVect.begin(), ii) << endl;
else
cout << "Value not found." <<end1;
return 0;
Объявляемый в программе контейнер имеет тип vector<int>, а итератор — тип vector<int>: : iterator. Каждый стандартный контейнер объявляет свой собственный вложенный класс iterator.
Далее мы вкратце рассмотрим различные формы итераторов.
Входные, выходные и поступательные итераторы
Простейший из итераторов — входной. Он может перемещаться по контейнеру только в поступательном направлении и допускает только чтение данных. Первые два параметра алгоритма find (), например, должны быть входными итераторами. Выходной итератор отличается от входного правом доступа. Он допускает только запись данных в контейнер.
К обеим этим формам итераторов можно применять, по меньшей мере, операцию неравенства (!=), разыменования (*) и инкремента (++).
Ниже показан пример копирования массива в вектор при посредстве выходного итератора и алгоритма copy (). Его последним параметром может быть любой выходной итератор. На самом деле тот же итератор здесь используется и как входной — в операторе вывода.
#include <algorithm>
#include <vector>
#include <iostream>
using namespace std;
double dArr[10] =
{1.0, 1.1, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9};
vector<double> dVect(lO);
int main()
{
vector<double>::iterator oi = dVect.begin ();
copy(dArr, dArr + 10, oi);
while (oi != dVect.endO) {
cout << *oi << endl;
oi++;
} return 0;
}
Итераторы потоков
Собственно, только входные и только выходные итераторы имеют смысл в основном при работе с потоками ввода-вывода, которые могут быть допускать либо только извлечение, либо только передачу данных. Любые контейнеры стандартной библиотеки генерируют более сложные, итераторы, которые, естественно, могут применяться и в качестве простых входных или выходных. / Вы уже хорошо знакомы со стандартными потоками cin и cout, извлечение и передача данных из которых производится операциями >> и <<. Однако возможен другой метод работы с этими потоками, при котором входной или выходной объект iostream преобразуется в итератор. Затем его можно передавать как аргумент стандартным алгоритмам.
Например, ниже показано, как можно применить выходной итератор для вывода на экран содержимого контейнера.
#include <algorithm>
#include <vector>
#include <iostream>
using namespace std;
int main( ) {
vector<int> iVect(lO);
for (int i=0; i<10; i++) iVect[i] = i;
cout<< "The vector contents are: { ";
copy(iVect.begin (),
iVect.endf), ostream_iterator<int>(cout, " "));
cout << "}." << endl;
return 0;
}
Поступательный итератор допускает как чтение, так и запись в контейнер. Однако, как и в случае двух предыдущих, возможен только инкремент, но не декремент итератора. Поступательные итераторы могут использоваться, например, в алгоритме replace (), который определяется так:
template <class Forwardlterator, class T>
void replace(Forwardlterator first,
Forwardlterator last,
const T &old_value,
const T &new_value);
Этот алгоритм заменяет все значения old_value, содержащиеся в контейнере, на new_value.
Двунаправленные итераторы
Двунаправленные итераторы допускают чтение и запись данных и к ним можно применять операции как инкремента, так и декремента. Такие итераторы могут быть, например, аргументами алгоритма reverse () , который меняет порядок элементов контейнера на обратный:
template <class Bidirectioriallterator>
void reverse(Bidirectionallterator first,Bidirectionallterator.last);
Такой алгоритм может быть полезен, если, скажем, из контейнера, уже сортированного в восходящем порядке, вы хотите получить контейнер с нисходящей сортировкой.
Итераторы произвольного доступа
Эти итераторы являются наиболее универсальными с точки зрения возможностей доступа. Их можно использовать для произвольного чтения и записи данных контейнера. (Обычные указатели принадлежат, кстати, к этому виду итераторов.) Такие итераторы участвуют в алгоритмах сортировки, входящих в стандартную библиотеку.
Алгоритм random_shuffle, также требующий итераторов произвольного доступа, случайным образом переставляет значения элементов в указанном диапазоне контейнера:
template <class RandomAccessIterator>
void random shuffle(RandomAccessIterator first, RandomAccessIterator last);
Итераторы вставки
Для вставки значений в контейнер применяются итераторы вставки. Их называют также адаптерами, поскольку они преобразуют контейнер в итератор, т. е. адаптируют его к специальному использованию в алгоритмах вроде copy (). Имеется три вида итераторов вставки:
Начальные адаптеры, вставляющие объекты в начало контейнера, например, списка (при этом вставленные элементы данных оказываются расположенными в порядке, обратном исходному).
Конечные адаптеры, присоединяющие объекты в конец контейнера.
Адаптеры вставки, вставляющие данные перед произвольным элементом контейнера.
При вставке данных в контейнер может произойти перемещение уже находившихся там данных, из-за чего некоторые итераторы станут недействительными. Это может случиться в случае вектора, но не списков, в которых данные при вставке не смещаются.
В типичном случае адаптер вставки применяется после поиска некоторого значения, как показано в следующем примере.
////////////////////////////////////////////////////////////////
// Inserter.срр: Демонстрация итераторов вставки. //
#include <algorithm>
#include <list>
#include <iostream>
#pragma hdrstop
#include <condefs.h>
using namespace.std;
int iArr[5] = (1, 2, 3, 4, 5);
//
// Функция вывода содержимого списка.
//
void Display(list<int> &1, const char *label)
(
cout << label<< ": { ";
copy (1 .begin (), 1.end(),
ostream_iterator<int>(cout, " "));
cout << "}" << endl;
}
int main(void) {
list<int> iLst; // Создание объекта списка.
// Копирование массива в список в обратном порядке:
copy(iArr, iArr + 5, front_inserter(iLst));
Display(iLst, "Before insertion");
// Поиск значения З:
list<int>::iterator i = find(iLst.begin(),
iLst.end(), 3) ;
// Вставка массива в список:
copy(iArr, iArr + 5, inserter(iLst, i));
Display(iLst, "After insertion ");
cin.ignore ();
return 0;
}
Рис. 11. 1 показывает результат работы программы. Можно отметить различие между inserter (iLst, i-Lst. begin ()) и front inserter (iLst). Первый адаптер вставляет данные в контейнер в прямом, а второй — в обратном порядке.
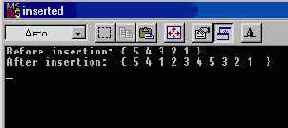
Рис. 11.1 Демонстрация адаптеров
Функции итераторов
Имеются две функции, которые могут оказаться полезными при работе с итераторами. Это advance () и distance (.) .
Функция advance () выполняет инкремент или декремент итератора указанное число раз. Ей передается итератор и число, определяющее число повторений инкремента или декремента (при отрицательном аргументе). Допустим, вам требуется найти некоторый элемент списка и установить итератор на несколько позиций за ним. Вы можете написать:
list<int> :: iterator i = find (iLst .begin (), iLst.endO, 3);
advance(i, 2); // Сдвигает итератор на 2 позиции вперед.
С функцией distance () вы уже встречались в примере параграфа “Итераторы контейнеров”, где с ее помощью выяснялась позиция итератора по отношению к началу вектора. Эта функция определяет количество инкрементов, которые нужно выполнить для перехода от одного итератора к другому. Она перегружена:
template <class Forwardlterator> iterator_traits<Forward!terator>::
difference_type distance(Forwardlterator first, Forwardlterator last) ;
template <class Forwardlterator, class Distance>
void distance(Forwardlterator first,
Forwardlterator last. Distance &n) ;
В упомянутом примере функция применялась в своей первой, несколько пугающей, форме, но на деле она проще второй, устаревшей. Она возвращает расстояние между итераторами как свое значение. Вторая форма функции передает расстояние в третьем параметре. Функция аккумулирует значение в этом параметре, поэтому его требуется перед вызовом инициализировать:
int d = 0;
distance (iLst, i, d);
Карты и мультикарты
Карты являются ассоциативными контейнерами и очень похожи на множества за исключением того, что в картах с ключами можно связать объекты произвольного типа. Ключ, таким образом, может служить своего рода индексом, по которому можно получить доступ к ассоциированному объекту. Соответственно, на картах определена операция индексации.
Ключевые значения в картах должны быть уникальны, в мультикартах они могут повторяться. Данные хранятся сортированными по ключевым значениям.
В общем, работа с картами практически ничем не отличается от работы с множествами. Только объявление карты выглядит несколько по-другому, поскольку в нем нужно указать дополнительно тип ассоциированных объектов.
Создание карт
В объявлении карты (мультикарты) требуется указать три аргумента шаблона: тип ключа, тип ассоциированного значения и класс функционального объекта, которым будет определяться способ упорядочения ключей. Обычно для простоты типу карты присваивается новое имя:
typedef map<string, double, less<string> > map_type;
Ключи такого контейнера будут строками, а ассоциированные объекты — значениями типа double. Сортирована карта будет в соответствии с алфавитным порядком ключей.
Кроме того, иногда бывает удобно объявить имя для типа элемента карты (т. е. по сути структуры, состоящей из ключа и ассоциированного типа объекта; подобные типы определяются с помощью шаблона pair<Tl, Т2>):
typedef map type::value_type val_type;
Обычно создается пустая карта, а затем в нее вводятся элементы функцией insert () . Возможно также конструирование новой карты из части уже существующей. При этом конструктору передаются, как обычно, два итератора.
Действия над картами
Важнейшие действия, выполняемые с картами и мультикартами — это поиск и извлечение данных по заданному ключу. Вообще-то карты в этом смысле практически полностью аналогичны множествам и имеют те же функции-элементы. Ниже приводится программа, демонстрирующая вариант “записной книжки” на основе мультикарты, которая может хранить несколько телефонных номеров для одного и того же имени-ключа. Нечто подобное мы уже делали в главе 8, когда говорили о перегрузке операции индексации, но индекс должен быть уникальным, а мультикарта позволяет иметь повторяющиеся ключи.
///////////////////////////////////////////////////////
// Multimap.срр: Макет телефонной книжки на основе multimap.
//
#include <iostream>
#include <iomanip>
#include <map>
#pragma hdrstop using namespace std;
struct Phone {
long pn;
Phone(long n = 0): pn(n) {} };
typedef multimap<string. Phone, less<string> > map_type;
typedef map type::value type val type;
typedef map_type::iterator i_type;
//
// Выводит элемент multimap (т.е. пару (string. Phone)).
//
ostreams operator“(ostream& os, const val_type& v)
{
os << setiosflags(ios::left)<< setfill('.')
<< setw(20) << v.first
<<resetiosflags(ios::left) << setfill('0')
<< setw(3) << v.second.pn / 10000 << "-"
<< setw(4)<< v.second.pn % 10000 << setfill(' ');
return os;
}
//
// Выводит "структуру" Phone.
//
ostreamS operator“(ostreamS os. Phone p)
(
os << setw(20) << "" << setfill('0')
<< setw(3) << p.pn / 10000 << "-"
<< setw(4)<< p.pn % 10000<< setfill(' ');
return os;
}
//
// Распечатка всех номеров, относящихся к одному имени.
// Возвращает итератор, ссылающийся на первую запись с
// другим именем. Обратите внимание на функцию
// equal range(), возвращающую структуру pair.
//
i_type Retrieve(ostreams os, map_type& mp, string name)
{
pair<i__type, i type>
r = mp.equal_range(name);
// Временная карта, конструированная по паре итераторов:
map_type b(r.first, r.second);
if (b.empty())
cout << "*** No such name! ***" << endl;
else {
i type p = b. begin ();
os << *p++ << endl; // Распечатать ключ и номер.
while (p != b.end())
os << (p++)->second << endi; // Для остальных
// только номер.
} return r.second;
}
//
// Распечатка всей карты.
//
void Printout'(ostream& os, map_type& mp, i_type from)
{
while (from != mp.endO) // Если не пустая,
// распечатать
from = Retrieve (os, mp, from->first);
// все номера
// первого ключа
//и перейти к
// следующему.
os << "*** End of the book ***" << endl;
}
ostreamS operator<<(ostreamb os, map_type& v) {
Printout (os, v, v.begin ());
return os;
}
int main() {
map type book;
// Попробуем распечатать пустую карту...
cout << "Contents of a new book:" << end1;
cout << book << endl;
book.insert(val_type("Petrov", 1653318));
book.insert(val_type("Ivanov", 2640535));
book.insert(val_type("Sidorov", 2340711));
book.insert(val_type("Ivanov", 4720415));
book.insert(val_type("Petrov", 1770212));
book.insert(val_type("Pavlov", 5551703));
book.insert(val_type("Ivanov", 4722306)) ;
// Распечатка.
cout << "Contents of the phone book:" << endl;
cout << book << end1;
// Поиск отдельных имен.
cout << "Searching Petrov... " << endl;
Retrieve(cout, book, "Petrov");
cout << "Searching Kozlov... " << end1;
Retrieve(cout, book, "Kozlov");
return 0;
}
Поиск нужного имени в этой программе выполняется функцией equal_range (), которая возвращает пару итераторов (структуру pair), ссылающихся на начало и конец диапазона с одним и тем же заданным ключом (если он присутствует).
Результат запуска программы показан на рис. 11.2.
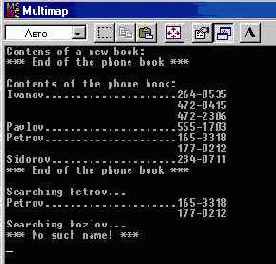
Рис. 11.2 Вывод программы Multimap
Контейнеры
В стандартной библиотеке имеется десять шаблонов классов, реализующих различные структуры данных. Их перечень уже приводился в таблице 10.1. Каждый контейнер имеет свой тип iterator, через представители которого вы получаете доступ к данным. Благодаря тому, что контейнеры — это шаблоны, они обладают чрезвычайной общностью. В них можно хранить объекты, указатели на них и даже другие контейнеры, создавая, таким образом, многоуровневые структуры данных.
Есть некоторые основные принципы работы контейнеров, о которых всегда следует помнить. Среди них можно сформулировать следующие:
В За запись объекта в контейнер отвечает конструктор копии объекта. При копировании одного контейнера в другой может быть важна перегруженная операция присваивания.
Контейнеры сами автоматически выделяют и освобождают память по мере надобности.
Когда программа уничтожает контейнер, она первым делом вызывает деструкторы для всех содержащихся в нем объектов. (Это не касается случая, когда в контейнере хранятся не объекты, а указатели на них.)
Лексикографическое сравнение
Такое страшное название алгоритма означает всего-навсего, что он выполняет сравнение содержимого двух контейнеров, аналогичное сравнению текстовых строк. Элементы контейнеров могут быть любого типа, лишь бы для них была объявлена операция “меньше” (или какая-либо функция, задающая отношение сравнения):
bool
lexicographical_compare (Inputlteratorl first1,
Inputlteratorl last1,
Inputlterator2 first2,
Inputlterator2 last2);
bool lexicographical compare(Inputlteratorl first1,
Inputlteratorl last1,
Inputlterator2 first2,
Inputlterator2 last2,
Compare comp);
Алгоритм возвращает true, если содержимое первого контейнера меньше, чем второго.
Множества и мультимножества
Множества — это наборы уникальных значений; мультимножества допускают повторяющиеся значения. В остальном они совершенно идентичны, так что в дальнейшем я буду говорить просто о “множествах”.
Множество представляет собой ассоциативный контейнер с быстрым доступам к значениям элементов. Значения элементов в множестве принято называть ключами. Программа может быстро определить, находится ли данный ключ в множестве.
Элементы множества всегда сортированы. Поэтому поиск нужного ключа очень прост и эффективен.
Что касается последовательных операций и прямого доступа, то тут множества далеки от совершенства. Набор функций-элементов у множеств невелик по сравнению с другими контейнерами.
Создание множеств
Объявляются множества несколько сложнее, чем рассмотренные до сих пор контейнеры, так как при этом необходимо указать функциональный объект, который будет использоваться при упорядочении элементов:
set<double, less<double> > dset;
Обязательно вставьте пробел между двумя правыми угловыми скобками, а то компилятор примет их за операцию сдвига и откажется транслировать программу.
Удобно переименовать представитель шаблона:
typedef set<double, less<double> > set_type;
set type dset;
Множество, как и другие контейнеры, можно создать из диапазона элементов другого контейнера:
double darr[6] = (1.0, 2.0, 2.5, 4.5, 3.5, 2.5};
set_type dset(darr, darr + 6) ;
В каком бы порядке ни следовали элементы в исходном контейнере, в множестве они окажутся сортированными.
Если в множество set вводятся повторяющиеся элементы, они игнорируются. В multiset ключ будет содержаться столько раз, сколько раз он вводился.
Действия над множествами
Как я сказал, функций у множеств сравнительно немного. Функции insert () и erase () имеют дополнительную форму с одним параметром, специфицирующим ключ, который нужно добавить или удалить из множества:
dset.insert (3.14);
dset.erase(3.5);
Функции lower bound () и upper bound () возвращают соответственно итератор элемента, который больше или равен, и элемента, который больше указанного ключевого значения. Пример использования этих функций показан в приведенной ниже программе.
Функция count () возвращает 'число вхождений в множество указанного ключа. В set функция может возвращать только 0 или 1. Вызов этой функции — простейший способ определить, входит ли ключ в множество.
Следующая программа иллюстрирует эти функции множеств.
#include <iostream>
#include <set>
#pragma hdrstop
#include <condefs.h>
using namespace std;
// Дать имя типу множества;
typedef multiset<double, less<double> > set_type;
//
// Операция передачи множества в поток.
//
ostream &operator“(ostream Sos, const set_type &c)
(
cout<< "{ ";
copy(c.begin (), c.end(),
ostream_iterator<set_type::value_type>(os, " "));
os << "} Size: "<< c.sizeO;
return os;
}
int main() {
set type dset;
cout << "Inserting... ";
for (int i=8; i>0; i--) { // Ввести элементы
dset.insert (i); //в множество.
cout << i << " ";
} cout<< end1;
cout.setf(ios::fixed);
cout.precision (1) ;
cout << "Initial set : " << dset<< end1;
dset.erase (2.0); // Удалить 2.0,если есть.
cout << "2.0 erased :" << dset<< endl;
dset.insert(4); // Добавить лишние четверки.
dset.insert (4); //
cout << "4's inserted : " << dset << endl;
cout<< "Count of 4.0 :"<< dset.count (4.0)<<endl;
// Сосчитать их.
set type::iterator pi =dset.lower_bound(2.5),
p2 =dset.upper bound(6.5);
dset.erase (pi, p2); // Найти диапазон значений
// и удалить его.
cout << "Erase 2.5-6.5: " << dset<< end1;
return 0;
}
Программа выводит:
Inserting. ..87654321
Initial set : ( 1.0 2.0 3.0 4.0 5.0 6.0 7.0 8.0 } Size: 8
2.0 erased : {1.0 3.0 4.0 5.0 6.0 7.0 8.0 ) Size: 7
4's inserted : { 1.0 3.0 4.0 4.0 4.0 5.0 6.0 7.0 8.0 }Size: 9
Count of 4.0 : 3
Erase 2.5-6.5: { 1.0 7.0 8.0 } Size: 3
Накопление
Накопление, или аккумуляция — это перебор заданного диапазона контейнера с суммированием (иди перемножением, или какой-то иной комбинацией) элементов в некоторой итоговой переменной. По умолчанию выполняется суммирование:
#include <numeric> double sum = accumulate(v.begin (), v.end(), 0.0);
Третий параметр алгоритма — начальное значение аккумулятора. При суммировании это обычно ноль. В качестве четвертого параметра можно задать функциональный объект, определяющий аккумулирующую операцию. Вот, например, как вычисляется произведение всех элементов вектора:
#include <numeric>
#include <functional>
double product = accumulate(v.begin(), v.end(),
1.0, multiplies<double> ());
Очереди
Очередь отличается от стека порядком извлечения элементов: если в стеке операция pop () удаляет самый последний из помещавшихся в него элементов, то в очереди там же операция удаляет наиболее “старый” элемент. Получить значение этого элемента можно, вызвав функцию front ().
Очередь может быть конструирована на основе либо списка, либо deque. Вот пример, аналогичный примеру со стеком из предыдущего параграфа:
#include <queue>
#include <list>
queue<int, list<int> > iQueue;
for (int i=0; i<10; i++) iQueue.push (i);
while (!iQueue.empty ()) {
cout << iQueue.front() << end1;
iQueue.pop ();
}
Очереди deque
Контейнеры deque (формально это сокращение означает “двусторонняя очередь”) комбинируют в себе свойства списков и векторов. Они допускают прямой доступ к элементам, но эффективно работают при вставках и удалениях.
У deque имеется операция индексации и отсутствуют функции, связанные с сортировкой, так как эти контейнеры могут работать со стандартными сортировками. В остальном они похожи на списки.
Операции над строками
Для стандартных строк перегружен ряд операций.
Операция присваивания позволяет присвоить стандартной строке другую строку, строку С (или литерал), отдельный символ. Все показанные ниже присваивания допустимы:
char с = ' С ';
char cs[20] = "С string.";
string sOld("Source string.");
string sNew;
sNew = sOld;
sNew = cs;
sNew = "Literal string.";
sNew = c;
Перегруженная операция сложения выполняет конкатенацию строк, причем возможна как конкатенация двух строк с присвоением результата третьей строке, так и присоединение строки в конец другой строки с помощью присваивания +=:
string si("First"), s2("Second");
string s3;
s3 = si + " " + s2;
si += s2;
Строки можно индексировать. При обычной нотации индексации проверки диапазона не делается. Однако можно применить функцию at (), также возвращающую ссылку на символ строки с указанным индексом. В этом случае при выходе за текущую длину строки выбрасывается исключение out_of_range:
string s("A short string.");
try {
cout<< s.at(30) << endl;
) catch(out_of_range e) {
cout << "Range error: "<< end! << e.what() << endl;
}
Этот фрагмент кода выводит:
Range error:
position beyond end of string in function:
basic_string::at(size_t)
index: 30 is greater than max index: 15
Наконец, для стандартных строк перегружен весь набор операций отношений: равенство, неравенство, “больше”, “меньше” и т. д. Операции < и > производят лексикографическое сравнение в соответствии с алфавитным порядком.
Перестановка
Алгоритм random_shuffle () производит случайную перестановку элементов контейнера:
void random_shuffle(RandomAccessIterator first,
RandomAccessIterator last);
В качестве третьего аргумента можно указать функциональный объект с целым параметром, задающим диапазон генерируемых им случайных чисел.
Алгоритм может быть полезен не только для задач вроде тасовки колоды карт, но и для подготовки, например, тестовых наборов данных для программ сортировки и т. п.
Подсчет
Алгоритм count () осуществляет подсчет числа элементов контейнера с указанным значением. Алгоритм count_if() выполняет подсчет элементов, для которых выполняется условие заданного предиката:
void count(Inputlterator first, Inputlterator last,
const T& value, Size& count) ;
void count if(Inputlterator first, Inputlterator last,
Predicate p, Size& count);
Результат подсчета возвращается в четвертом параметре.
Поиск и замена
С алгоритмом поиска вы уже встречались не раз:
Inputlterator
find(Inputlterator first, Inputlterator last,
const T& value);
Inputlterator
find(Inputlterator first, Inputlterator last,
Predicate pred) ;
Вторая форма возвращает итератор первого элемента, для которого истинен указанный предикат.
Алгоритмы замены replace () и replace_if() позволяют заменять существующие значения контейнера новыми:
void replace(Forwardlterator first, Forwardlterator last,
const T& value, const T& new_value) ;
void replace_if(Forwardlterator first, Forwardlterator last,
Predicate pred, const T& new_value) ;
Приоритетные очереди
Наконец, последний из рассматриваемых здесь контейнеров стандартной библиотеки — это приоритетная очередь. Она строится на основе вектора или deque. От обычной очереди она отличается тем, что вне зависимости от порядка размещения элементов первым будет извлекаться наиболее “критический” из них. Критичность, или приоритет, элемента определяется заданным функциональным объектом отношения (по умолчанию — “меньше”). Наиболее приоритетный (наибольший) элемент помещается на вершину очереди (его значение доступно посредством функции top ()) и удаляется первым (функция pop ()).
Создание и действия с приоритетной очередью
При конструировании очереди в общем случае указывается тип элементов, тип контейнера-основы и функциональный объект, определяющий приоритеты. Контейнером-основой для приоритетной очереди может быть вектор или deque.
Нужно сказать, что шаблоны стеков и очередей имеют аргументы по умолчанию. Тип контейнера и отношение (для приоритетной очереди) указывать, вообще говоря, не обязательно. Так, для стека и очереди тип контейнера по умолчанию — deque, для приоритетной очереди — vector, а операция отношения — “меньше”.
Вот маленький пример, моделирующий составление списка неотложных дел в порядке их важности:
////////////////////////////////////////////////////
// Priority.срр: Демонстрация приоритетной очереди.
//
#include <iostream>
#include <string>
#include <queue>
#include <deque>
#pragma hdrstop
using namespace std;
class ToDo {
int priority;
string doit;
public:
ToDo(int p = 0, string d = ""): priority(p), doit(d) {}
bool operator<(const ToDo &arg) const { return priority < arg.priority; }
friend ostream &operator<<(ostreams, const ToDo&);
};
ostream &operator<<(ostream &os, const ToDo &t) {
os << t.priority << " - " << t.doit;
return os;
}
int main() {
priority_queue<ToDo, deque<ToDo>, less<ToDo> > todo;
// Разместим некоторые неотложные дела... todo.push(ToDo(3, "Finish the program you started yesterday."));
todo.push(ToDo(7, "Write a letter to X."));
todo.push(ToDo(4, "Buy some food for dinner."));
todo.push(ToDo(1, "Call your publisher."));
// Распечатать список в порядке срочности. while (!todo.empty()) {
cout << todo.top() << endl;
todo-pop() ;
)
return 0;
)
Программа выводит:
7 - Write a letter to X.
4 - Buy some food for dinner.
3 - Finish the program you started yesterday.
1 - Call your publisher.
Сортировка
С сортировкой мы уже встречались, правда, в виде функции контейнера (при изучении списков — их нельзя сортировать по-другому), а не отдельного алгоритма. Сортировка по умолчанию производится в восходящем порядке (используется операция < для сравнения элементов):
void sort(RandomAccessIterator first, RandomAccessIterator last);
void sort(RandomAccessIterator first,
RandomAccessIterator last. Compare comp);
Состав библиотеки
Если более конкретно рассмотреть состав библиотеки стандартных шаблонов (исключив пока из рассмотрения строки), то в ней можно выделить следующие компоненты:
Итераторы, которые в некоторых отношениях подобны указателям. Это фундаментальное понятие STL; итераторы обеспечивают доступ к элементам данных контейнеров.
Контейнеры представляют собой структуры или наборы данных, такие, как списки, векторы, очереди, реализованные как шаблоны классов.
Уже упомянутые алгоритмы, представляющие собой шаблоны функций, оперирующих на данных контейнеров. Например, алгоритм может сортировать объекты, являющиеся элементами вектора или списка. Функции эти не обладают специфическими “знаниями” о типах и структурах, на которых они действуют.
Последнее, кстати, означает, что STL, если рассматривать ее как целое, не является объектно-ориентированной, поскольку данные и методы (т. е. алгоритмы) между собой не связаны. Организовать на основе библиотеки адекватные задаче классы и является обязанностью программиста, если он хочет написать действительно объектно-ориентированную, иерархически организованную программу.
Вместе с STL в C++Builder предусмотрены различные дополнительные средства, например, класс комплексных чисел и средства обработки ошибок.
Создание строк
Конструировать строки можно многими способами; можно создать пустую строку (конструктор по умолчанию), можно инициализировать строку литералом, присваиванием литерала или копированием, можно зарезервировать указанное число символов, инициализировав в то же время строку литералом меньшей длины, можно создать строку из стандартного контейнера (например, вектора), содержащего символы, и т. д. Ниже приводится ряд примеров конструирования строк.
string sEmpty;
string sLiteral("A string from literal.");
string sAssign = "A string by assign.";
string sCopy(sLiteral);
string sPart(sCopy, 14, 7);
string sFill(32, '#') ;
Пояснений, вероятно, требуют только два последних конструктора. Предпоследний создает строку из уже существующей, выделяя ее подстроку длиной 7 символов, начиная с индекса 14. Последний конструктор создает строку длиной 32 символа, заполняя ее символами ' # '.
Списки
Списки — двусвязные линейные структуры данных, т. е. каждый элемент имеет два указателя для ссылки на два других элемента. Списки занимают ровно столько памяти, сколько необходимо для хранения наличных элементов. Вставка и удаление из списка очень эффективны. Слабым местом списка является доступ к элементам. Прямой доступ, как в векторах, невозможен. Для поиска нужного элемента приходится двигаться по списку, начиная с самого начала.
Создание списков
Существуют различные способы конструирования списков.
#include <list>
list<int>ilist;
list<double>dlist(20, 1.0);
list<MyType>mtlist(10) ;
Эти объявления имеют тот же смысл, что и соответствующие объявления для векторов. Так же как и вектор, список можно конструировать, инициализировав содержимым другого контейнера:
int iarr[5] = {1, 2, 3, 4, 5};
…
list<int> linti(iarr, iarr + 5);
В списке можно хранить любой тип данных, при условии, что он поддерживает те функции-элементы (конструкторы и проч.), о которых говорилось выше при обсуждении векторов.
Действия над списками
Поскольку список занимает ровно столько памяти, сколько необходимо, для него не имеет смысла понятие вместимости. Поэтому у списков нет функций capacity () и reserve (). Невозможно и обращение к элементам по индексу.
В остальном над списками можно производить все те операции, что описывались в предыдущем параграфе о векторах. Но следует упомянуть о некоторых дополнительных возможностях списков.
Помимо известных вам уже методов push back() и pop back (), имеются функции push_front () и pop_front () для добавления или удаления элемента в начале списка.
Функция remove () удаляет из списка все элементы с указанным значением.
Функция unique () удаляет все повторяющиеся элементы (стоящие;
подряд, поэтому функцию имеет смысл применять только на сортированных списках), оставляя только первое вхождение элемента с данным значением.
Функция reverse () обращает порядок элементов в списке.
Функция sort () (без аргумента) производит сортировку списка в соответствии с операцией “меньше”, т. е. в восходящем порядке. Можно задать в качестве аргумента функциональный объект, реализующий отношение, в соответствии с которым нужно сортировать список:
#intlude <functional> linti.sort(greater_equal<int>());
Функция sort() сохраняет относительный порядок следования повторяющихся элементов. Такого рода сортировку называют стабильной.
Функция merge () выполняет слияние сортированного списка с другим сортированным списком. Элементы второго списка удаляются. Как и в случае sort (), можно задать второй аргумент — функциональный объект, определяющий отношение сортировки.
Заметим, что списки нельзя сортировать с помощью стандартных алгоритмов, поскольку для них требуется прямой доступ к элементам контейнера.
Функция splice () является специальным вариантом вставки. Она удаляет вставляемый элемент или элементы списка, из которого производится вставка.
Описанные функции частично иллюстрирует следующая программа.
#include <iostream>
#include <list>
#pragma hdrstop
#include <condefs.h>
using namespace std;
//
// Операция передачи списка в поток.
//
template<class T>
ostream &operator“(ostream &os, const list<T> &c)
{
cout << "{ ";
copy (c. begin (), c.end(),
ostream_iterator<T> (os, " "));
os << "} Size: " “ c.size();
return os;
}
int main() {
int iarrl[5] = {5, 7, 3, 1, 9};
list<int> lintl(iarr1, iarr1 + 5);
cout<< "Initial list : "<< linti << endl;
linti.sort (); // Сортировка.
cout << "After sort : "<< lint1 << end1;
int iarr2[6] = {6, 2, 4, 8, 2, 6};
list<int> lint2(iarr2, iarr2 + 6);
cout << "Second list : " << lint2 << end1;
lint2.sort () ;
lint2.unique(); // Удаление повторов.
cout<< "Sorted unique: " << lint2 “ endl;
linti.merge(lint2); // Слияние.
cout <<"After merge : " << lint1 “ end1;
linti.reverse (); // Обращение порядка.
cout << "After reverse: "<< lint1 << end1;
return 0;
}
Программа выводит:
Initial list : {57319} Size: 5
After sort : {13579} Size: 5
Second list : {624826} Size: 6
Sorted unique:(2468) Size: 4
After merge :{123456789} Size:9
After reverse:{987654321}Size:9
Стандартные строки
Под стандартными строками понимают объекты, принадлежащие шаблону basic_string, чаще всего его классам-представителям string или wstring. В повседневном .программировании применяется почти исключительно класс string.
Стандартные строки имеют ряд преимуществ перед строками “в стиле С”, т. е. строками с ограничивающим нулем, хранящимися в массивах типа char. Строки стандартной библиотеки шаблонов можно считать контейнерами, однако они реализованы совершенно отдельно от остальных контейнеров, рассматривавшихся в предыдущем разделе.
Чтобы можно было работать со стандартными строками, необходимо включить в программу заголовок string. При этом, кстати, автоматически подключается заголовок С string, h, так что вы можете при этом пользоваться стандартными функциями С для строк, ограниченных нулем.
Стеки
Стек — очень простая структура данных. В STL можно организовать три разновидности стеков: на основе вектора, на основе списка и на основе deque. Функционально они не отличаются друг от друга.
Создание и действия со стеками
При конструировании стека нужно указать не только тип хранящихся в нем объектов, но и тип контейнера, на основе которого стек будет реализован:
#include <stack>
#include <vector>
stack<int, vector<int> > iStack;
Функция push () помещает указанное значение на вершину стека;
функция pop () удаляет из стека верхнее значение. Получить значение с вершины стека можно функцией top ():
for (int i=0; i<10; i++) iStack.push(i) ;
while (!iStack.empty()) {
cout<< iStack.topO << endl;
iStack.pop();
}
Удаление элементов
Удаление элементов контейнера с указанным значением выполняется алгоритмами remove () и remove_if:
Forwardlterator
remove(Forwardlterator first, Forwardlterator last,
const T& value) ;
Forwardlterator
remove if(Forwardlterator first, Forwardlterator last,
Predicate pred) ;
Необходимо заметить, что эти алгоритмы не уменьшают числа элементов в контейнере. Они только сдвигают элементы, которые должны остаться в новом наборе, к его началу, и возвращают итератор конца нового набора элементов. Чтобы действительно удалить ненужные элементы, нужно применить метод контейнера erase ():
array.erase(remove(array.first(), array.end(), value),
array.end());
Алгоритм unique () удаляет из контейнера все элементы с повторяющимися значениями, следующие друг за другом, оставляя только первый из них:
Forwardlterator remove(Forwardlterator first, Forwardlterator last);
Алгоритм возвращает итератор конца нового набора элементов.
Векторы
Вектор — это своего рода массив с “интеллектом”, помнящий свой размер и поддерживающий свою целостность. Они, среди прочих контейнеров, отличаются эффективностью доступа к элементам. К недостаткам следует отнести сложность вставки элементов в середину вектора, поскольку при этом приходится перемещать часть его содержимого.
Создание векторов
Объявления векторов могут выглядеть примерно так:
#include <vector>
vector<int> vint;
vector<double> vdouble (100);
vector<string> vstr(10);
vector<MyClass> myvect(20);
Короче говоря, вы можете создать либо пустой вектор, либо вектор указанного размера. Кроме размера, можно указать также начальное значение, которое будет присвоено всем элементам:
vector<int> vint1(24, -1);
Можно объявить вектор из объектов своего собственного класса. Следует при этом иметь в виду, что любой структурный тип должен иметь:
конструктор по умолчанию
конструктор копии
деструктор
операцию взятия адреса
операцию присваивания.
На самом деле для простых классов, не содержащих указателей на какие-либо динамические объекты, годятся те функции-элементы, что компилятор генерирует сам, за исключением разве что конструктора по умолчанию. (Он генерируется автоматически, только если вы не определили вообще никаких конструкторов. Создаваемые таким конструктором объекты будут содержать “мусор”.) Советую вам обязательно объявлять, хотя бы пустой, конструктор по умолчанию для классов, которые будут размещаться в контейнерах.
Естественно, потребуются еще какие-то механизмы присваивания и извлечения значений элементов данных создаваемого объекта и т. п. Но это вопрос внешний по отношению к функционированию контейнера.
Если вы хотите выполнять поиск или сортировку, потребуются операции равенства (==) и “меньше” (<).
Скелет класса, пригодного для помещения в вектор, может иметь такой вид:
class Coord {
int x, у;
public:
Coord() : x(0), у(0) {}
void set(int _x, int y) { x = x; у = _y; }
void get(int &_x, int &_y) { _x = x, _y = y; ) };
Для доступа к данным вектора применяется индексация:
vstr[3] = "Third value: ";
vdouble[10] = 3.3333333333;
cout<< vstr[l]<< vdouble[10] << endl;
Можно конструировать вектор с помощью итераторов, например:
int iArr[16] ;
vector<int> iVectl(iArr, iArr + 16);
vector<int> iVect2(iVect!.begin(), iVect!.end());
( Для обычного массива, как мы уже говорили, итератором является простой указатель. Второй из векторов конструируется из первого спецификацией его начального и конечного итераторов.)
Действия над векторами
Вектор характеризуется своим размером и вместимостью. Размер — это число элементов, хранящихся в векторе в настоящий момент. Вместимость показывает предел увеличения размера вектора без дополнительного выделения памяти.
Размер и вместимость вектора можно получить с помощью его методов size() и capacity():
cout <<"Size: "<< vdouble.size ()<<"Capacity: " << vdouble .capacity () <<end1;
Есть еще функция max_size(), которая возвращает верхний предел размера и вместимости, определяемый обычно размером наибольшего доступного блока памяти.
Функция resize () позволяет изменить размер массива. Функция is_empty () возвращает true, если вектор пуст (размер равен 0). Вместимость вектора можно изменить его функцией reserve (). Заблаговременное резервирование позволяет избежать частых автоматических выделений памяти:
vdouble.reserve (1000);
Функция clear () удаляет все элементы вектора.
Функция assign () присваивает указанное значение первым n элементам:
vdouble.assign (100, 1.0);
Альтернативная форма функции позволяет присвоить элементам значения из диапазона другого контейнера:
void assign (Input-Iterator first, Inputlterator last);
Функции front() и back () возвращают значения соответственно первого и последнего элементов вектора.
Наиболее часто используемыми функциями векторов являются, вероятно, erase () и insert (). Они служат для удаления и вставки элементов. При удалении элемента (или нескольких элементов) из вектора все последующие сдвигаются к началу. Эти функции перегружены; мы приводим только две формы insert ():
iterator erase (iterator position) ;
iterator erase (iterator first, iterator last) ;
iterator insert(iterator pos, const T& x);
void insert(iterator pos,
Inputlterator first, Inputlterator last) ;
Эти функции позволяют соответственно удалить элемент, удалить диапазон, вставить элемент и вставить диапазон элементов из другого контейнера.
С помощью функций push_back () и pop_back () вектор можно использовать как стек. Первая из них вставляет элемент в конец вектора, вторая — удаляет конечный элемент (она не возвращает его значение).
Вот небольшая иллюстрация:
#include <iostream>
#include <vector>
#pragma hdrstop
#include <condefs.h>
using namespace std;
//
// Вспомогательная функция для вывода содержимого контейнера
//
template<class T> void Display(const Т &с) {
cout<< "( " ;
copy(с.begin (), c.end(),
ostream_iterator<T::value_type> (cout, " "));
cout << "} Size: " << c.size() << endl;
}
int main ()
(
int iarr[5] = (1, 2, 3, 4, 5);
vector<int> vintl(iarr, iarr + 5);
cout << "Initial vector : ";
Display(vinti);
vector<int>::iterator p =
find(vinti.begin (), vintl.end(), 3);
vinti.erase (p);
cout << "After erasing 3: ";
Display(vinti);
vinti.insert (p, iarr, iarr + 3);
cout << "After insertion: ";
Display(vinti);
cout << "Pop and push : ";
vinti.pop_back();
Display(vinti);
vinti.push back(33);
cout << " Display(vinti);
vinti.pop_back ();
return 0;
}
Программа выводит:
Initial vector : {12345} Size: 5
After erasing 3: {1245} Size: 4
After insertion: {1212345} Size: 7
Pop and push : {121234} Size: 6
{ 1 2 1 2 3 4 33 } Size: 7
Полный список функций-элементов вектора вы можете найти в оперативной справке C++Builder'a.
Введение в библиотеку стандартных шаблонов
Состав библиотеки стандартных шаблонов можно разбить на две категории: алгоритмы и структуры данных. Из последних можно выделить стандартные строки, поскольку они реализованы совершенно независимо от остальных элементов библиотеки. Строки мы будем обсуждать отдельно и подробнее, чем все остальное.
Ввод и вывод строк
Наиболее прост вывод строк с помощью операции <<:
string s("This is a string!");
cout << s << end1;
По форме это ничем не отличается от вывода строки С. Ввод строки вроде бы тоже выглядит очень просто:
string s;
cin >> s;
Однако такой оператор считывает в строку только одно “слово” до первого пробельного символа. Чтобы прочитать всю введенную строку вплоть до ограничителя, нужно воспользоваться функцией getline ():
string s;
getline(cin, s, '\n');
Ограничитель ' \n ' можно было бы и не указывать, так как он принимается по умолчанию.
Заголовочные файлы
Стандартная библиотека C++ вводит новый стиль спецификации заголовочных файлов. Расширение .h опускается. Например, для подключения библиотеки алгоритмов нужно написать
#include <algorithm>
Компилятор автоматически укорачивает имя до восьми символов, добавляет .h и читает файл algorith.h из каталога $(BCB)\Include. На уровне исходного кода программы C++ получаются более мобильными, не привязанными к конкретной системе именования файлов.
Следующая таблица перечисляет стандартные заголовки STL с краткими описаниями контейнерных классов, которые они содержат.
Таблица 10.1. Контейнерные классы STL
|
Директива #include |
Класс контейнера |
||
| <bitset> | bitset — множества как битовые наборы. | ||
| <deque> | deque — двусвязные очереди; имя является сокращением от “double-end queue”. | ||
| <iist> | list — списки. | ||
| <map> | map, multimap — карты; это структуры, подобные массиву, но в которых роль “индекса” могут играть не только целые числа, но любые упорядоченные типы. | ||
| <queue> | queue, priority queue — очереди, т. е. структуры, организованные по принципу “первым вошел, первым вышел”. | ||
| <set> | set, multiset — множества. | ||
| <stack> | stack — стеки, организованные по принципу “последним вошел, первым вышел”. | ||
| <vector> | vector, vector<bool> — векторы, во многом подобные обычным массивам. |
Блок catch
За пробным блоком следует один или несколько обработчиков исключения, начинающихся ключевым словом catch. За ним следует объявление исключения в круглых скобках, аналогичное формальному параметру функции:
try {
}
catch(int. i) { // Перехватывает исключения типа int.
} catch(char* str) { // Перехватывает char*.
} catch (...) { // Перехватывает все остальное.
Если тип выброшенного в пробном блоке исключения совпадает или совместим (об этом позже) с типом в объявлении некоторого обработчика, то данный обработчик перехватывает исключение. Если нет, то поиск подходящего обработчика продолжается далее. Обработчик, в заголовке которого вместо объявления исключения стоит многоточие (...), перехватывает исключения любого типа; такой обработчик должен быть последним в ряду тех, что следуют за данным блоком try.
Если пробный блок не генерировал никакого исключения, управление, по выходе из него, передается первому оператору, следующему за последним из обработчиков исключений.
Блок try
Ключевое слово try начинает пробный блок операторов, показывая, что данный блок может генерировать исключение. Тело блока заключается в фигурные скобки. Оно может содержать вызовы функций, тело которых при этом тоже будет рассматриваться как принадлежащее пробному блоку. Другими словами, весь код, могущий прямо или косвенно исполняться при входе в блок, принадлежит пробному блоку:
try {
cout << "Входим в пробный блок..."<< end.1;
DangerousFunc(); // Вызов процедуры, способной
// генерировать исключение.
}
// Конец try-блока.
Блоки try могут быть вложенными.
Информация об исключении
Имеются три глобальные переменные, в которых хранится информация о текущем исключении (они объявлены в заголовке except, h):
_throwExceptionName содержит указатель на строку с именем типа исключения;
_throwFileNane содержит указатель на строку с именем файла, где произошло исключение;
_throwLineNumber — целое без знака, представляющее номер строки файла, где было выброшено исключение.
Чтобы эта информация стала доступной, на странице C++ диалога Project Options нужно установить флажок Location information в группе Exception handling (по умолчанию выключен). Он соответствует ключу командной строки -хр.
Вот пример:
////////////////////////////////////////////////////
// Loclnfo.cpp: Информация о точке выброса исключения.
//
#include <iostream.h>
#include <stdexcept>
#pragma hdrstop
#include <condefs.h>
void f() {
throw invalid_argument("Exception from f(): ");
}
int main() {
try { f () ;
}
catch(const exception &e) { cout << e.what()
<< _throwExceptionName << end1
<< " in file " << _throwFileName << end1
<< " line " << _throwLineNumber << end1;
}
return 0; }
Программа печатает:
Exception from f(): invalid argument
in file C:\Projects\Chl2\LocInfo\LocInfo.cpp line 8
Исключения и классы
Как уже упоминалось, выбрасывать можно не только выражения простых типов, но и объекты классов, определенных пользователем. Кроме того, нужно рассмотреть еще ряд вопросов, связанных с работой конструкторов и деструкторов во взаимодействии с механизмом исключений.
Исключения и стек
Когда выбрасывается исключение, управление передается некоторому обработчику; он должен принадлежать функции, еще находящейся на стеке вызовов программы (см. в главе 5 об окне стека вызовов). Но эта функция не обязательно будет текущей функцией (выбросившей исключение). Например, пробный блок и обработчики находятся в одной функции, а исключение выбрасывается некоторой функцией, вызываемой из пробного ; блока; между ними может тянуться целая цепочка вложенных вызовов.
В результате некоторой последовательности вызовов на стеке (физическом) будут находиться адреса возврата, передаваемые аргументы и локальные переменные вызванных к данному моменту функций, а также вспомогательная информация (формирующая кадры стека), которая используется кодом входа и выхода из функции.
При нормальном возврате из функции она удаляет со стека локальные переменные, вызывая соответствующий деструктор, если переменная — представитель класса. Затем она восстанавливает кадр стека вызывающей функции и исполняет инструкцию возврата. После этого вызывающая функция удаляет со стека передававшиеся аргументы, также вызывая при необходимости деструкторы.
Приведем небольшую иллюстрацию. Ниже показана программа, состоящая из main () и двух функций FuncA () и FuncB () . Главная функция создает объект класса S и передает его FuncA (), которая его модифицирует и передает в FuncB (). Затем управление возвращается к main () .
Листинг 12.2. Работа стека при вызовах функций
///////////////////////////////////////////////////
// Stack.срp: Работа стека.
//
#include <iostream.h>
#pragma hdrstop
#include <condefs.h>
struct S // Простой класс. {
int s;
S(int ss): s(ss) // Конструктор (преобразования из int).
{
cout << "Constructor for "<< s << endl;
} S (const S& src) // Конструктор копии.
{
s = src.s;
cout << "Copy constructor for " << s << endl;
}
~S() // Деструктор.
{
cout << "Destructor of " << s << endl;
} };
void FuncB(S obj)
{
cout << "In FuncB: got << obj.s endl;
cout << "Exiting FuncB..." << endl;
}
void FuncA(S obj)
{
cout << "In FuncA: got"<< obj.s << endl;
obj.s = 22; // Модифицирует полученную копию объекта и...
FuncB(obj); // ...передает ее FuncB().
cout << "Exiting FuncA..." << end1;
}
int main() {
S mainObj = 11; // Локальный объект.
cout << "In main..." << endl; FuncA(mainObj);
cout << "Exiting main..." << endl;
return 0;
}
Программа выводит следующие сообщения:
Constructor for 11
In main...
Copy constructor for 11
In FuncA: got 11
Copy constructor for 22
In FuncB: got 22
Exiting FuncB...
Destructor of 22
Exiting FuncA...
Destructor of 22
Exiting main...
Destructor of 11
Здесь видно, как создается копия объекта при передачи параметра (по значению) и как она удаляется при возврате из функции.
При появлении исключения нормального возврата не происходит. Требуемый обработчик может находиться на несколько позиций выше по стеку вызовов. Запускается механизм разматывания стека, удаляющий находящиеся на нем локальные объекты с вызовом деструкторов, как если бы происходил нормальный возврат из функций, находящихся еще на стеке вызовов.
Можно слегка модифицировать предыдущий пример, организовав пробный блок в main() и заставив FuncB() выбрасывать исключение в виде строки:
…
void FuncB(S obj)
{
cout << "In FuncB: got " << obj.s << endl;
cout << "Throwing exception..." << endl;
throw "Exception!";
cout << "Exiting FuncB..." << endl;
}
int main() {
S mainObj = 11; // Локальный объект.
cout << "In main..." << endl;
try {
FuncA(mainObj);
} catch(char* str) {
cout << "Gaught in main: " << str << end1;
} cout << "Exiting main..." << endl;
return 0;
}
Теперь программа выводит:
Constructor for 11
In main...
Copy constructor for 11
In FuncA: got 11
Copy constructor for 22
In FuncB: got 22
Throwing exception...
Destructor of 22
Destructor of 22
Caught in main: Exception!
Exiting main...
Destructor of 11
Временные копии объекта уничтожаются по-прежнему, хотя возврата из функции в обычном смысле слова не происходит.
Исключения, конструкторы и деструкторы
Следующие два параграфа посвящены процессам, происходящим при генерировании исключения в конструкторе класса.
Локальные (автоматические) объекты
Когда выброшено исключение, начинается разматывание стека с вызовом необходимых деструкторов. Однако деструкторы в этом случае вызываются только для полностью конструированных локальных объектов. Это означает, что если исключение выброшено в конструкторе объекта, для самого этого объекта деструктор вызван не будет. Будут вызваны только деструкторы его элементов-объектов и базовых классов. Поэтому, если объект содержал уже к этому времени указатели, например, на выделенную динамическую память, она освобождаться не будет. Возникнет утечка памяти.
Рассмотрите такой пример:
Листинг 12.4. Исключение в конструкторе
/////////////////////////////////////////////////////
// Construct.срр: Исключение в конструкторе. //
#inciude <stdio.h>
#include <stdlib.h>
#include <string.h>
#pragma hdrstop
#include <condefs.h>
void* operator new[](size_t size)
// Глобальная new[].
{
printf("Global new[].\n");
return malloc(size);
}
void operator delete[](void *p) // Глобальная delete[].
{
printf("Global delete[].\n");
free (p) ;
}
class Hold { // Класс, содержащий динамический массив char. char *ptr;
public:
Hold(char *str) // Конструктор преобразования из char*.
{
printf("Constructor.\n") ;
ptr = new char[strlen(str)+1] ;
strcpy(ptr, str) ;
// printf("Constructor: throwing exception...\n");
// throw "Exception!";
} ~Hold() // Деструктор.
{
printf("Destructor.\n") ;
delete [ ] ptr;
}
void Show() // Распечатка строки.
{
printf("My contents: %s\n", ptr);
} };
int main() {
try {
Hold h = "Some string."; // Попытка конструировать
// объект. h.Show() ;
} catch(char *str) {
printf("Message caught: %s\n", str);
}
printf("Exiting main...\n");
return 0;
}
Программа создает локальный в try-блоке объект класса Hold. Строка в конструкторе, выбрасывающая исключение, пока закомментирована, и программа выводит:
Constructor.
Global new[].
My contents: Some string.
Destructor.
Global delete [].
Exiting main...

Вопрос на сообразительность: почему мы для вывода сообщений пользовались в этом примере функцией библиотеки С printf (), а не потоковыми операциями C++?
Если же раскомментировать строку, будет выброшено исключение, причем, поскольку деструктор не полностью конструированного объекта не вызывается, операция delete [ ] для уже выделенной строки выполнена не будет:
Constructor.
Global new[].
Constructor: throwing exception...
Message caught:Exception!
Exiting main...
Отсюда можно сделать полезный методический вывод: ресурсы, подобные выделяемой памяти (например, графические объекты Windows), следует оформлять как классы, которые будут входить в целевой класс в качестве его элементов. Класс из предыдущего примера можно модифицировать примерно так:
class Hold { // Класс, содержащий динамический
// массив char. struct IChar { // Вложенный класс, инкапсулирующий
// массив. char *ptr;
IChar(char *str) {
printf("IChar: constructor.\n");
ptr = new char[strlen(str)+1];
strcpy(ptr, str) ;
}
~IChar() {
printf("IChar: destructor.\n") ;
delete [] ptr;
}
} iStr; // Элемент - объект IChar. public:
Hold(char *str) // Конструктор преобразования из char*.
iStr(str) // Инициализатор элемента iStr. {
printf("Constructor: throwing exception ...\n");
throw "Exception!";
} ~Hold() // Деструктор - ничего не делает.
{
printf("Destructor.\n");
} void Show() // Распечатка строки.
{
printf("My contents: %s\n", iStr.ptr);
} };
Как видите, действия по выделению и освобождению памяти возложены теперь на класс IChar. Он, конечно, не обязан быть вложенным, как я сделал здесь (зачем, и сам не знаю). Программа выводит:
IChar: constructor.
Global new[].
Constructor: throwing exception...
IChar: destructor.
Global delete [].
Message caught: Exception!
Exiting main...
Хотя, как видите, деструктор Hold и не вызывается, деструктор его полностью конструированного элемента iStr вызывается правильно и память освобождается.
Динамические объекты
Если объект создается с помощью операции new своего класса, и в конструкторе класса генерируется исключение, то деструктор класса не вызывается. В этом отношении все происходит совершенно так же, как описано выше для явных вызовов конструктора (т. е. для локальных объектов).
Хотя деструктор не вызывается, память объекта (не та, на которую он может ссылаться посредством указателей, а его собственная) автоматически удаляется. По сути, то же происходит и с локальными объектами, только там не полностью конструированный объект просто удаляется со стека, здесь же вызывается операция класса delete. Вот пример:
Листинг 12.5. Исключение в конструкторе динамического объекта
////////////////////////////////////////////////
// Dynamic.срр: Исключение при операции класса new.
//
#include <iostream.h>
#include <string.h>
#pragma hdrstop
#include <condefs.h>
const int MaxLen = 80;
class AClass {
char msg[MaxLen];
public:
AClass () // Конструктор, выбрасывающий исключение.
{ {
cout << "AClass: constructor." << endl;
cout << "Throwing exception..." << endl;
throw "Exception!";
}
~AClass() // Деструктор.
{
cout << "AClass: destructor."<< endl; }
void *operator new (size t size) // new класса.
{
cout<< "AClass: new." << endl;
return ::new char[size];
}
void operator delete(void *p) // delete класса.
{
cout << "AClass: delete." << endl;
::delete[] p;
}
};
int main() {
AClass *ap;
try {
ар = new AClassO; // Попытка выделить, объект.
}
catch(char *str) {
cout << "Caught a sring: " << str << endl;
)
return 0;
}
Эта программа выводит:
AClass: new.
AClass: constructor.
Throwing exception...
AClass: delete.
Caught a string: Exception!
Таким образом, при исключении память объекта освобождается операцией класса delete.
Классы исключений
Часто для обработки исключительных ситуаций используются классы, специально предназначенные для этой цели. Главное в управлении исключениями — отыскать нужный обработчик, а это делается путем сопоставления типа выброшенного объекта с типами, объявленными в обработчиках. Поэтому иногда для исключений определяют совершенно “пустые” классы, однако с уникальными именами.
Классы исключений программы могут быть организованы в иерархическую структуру. Схожие типы исключений объявляются в качестве производных одного и того же базового класса, являющегося их обобщением. Используя полиморфные механизмы, можно перехватывать только указатель или ссылку на базовый класс; полиморфизм обеспечит адекватную обработку исключения любого производного класса. Вот примерная схема:
class GenericFault { // Обобщенная ошибка.
public: virtual void Report ();
//
// Конкретные типы ошибок...
//
class OpenError: public GenericFault {
public:
void Report();
}
class BadHeader: public GenericFault { public:
void Report ();
class BadRecord: public GenericFault ( public:
void Report () ;
}
int main() {
try {
}
catch(GenericFault &err) { err.Report () ;
}
return 0;
}
Механика исключений
Следующие параграфы посвящены некоторым механизмам, которые нужно хорошо понимать, чтобы эффективно пользоваться возможностями управления исключениями.
О системных исключениях
Системные или процессорные исключения вроде деления на ноль невозможно обработать, пользуясь только механизмом исключений языка C++. Эти исключения сразу перехватываются операционной системой. Тем не менее, C++Builder поддерживает уже упоминавшееся в 4-й главе структурированное управление исключениями (SEH — Structured Exception Handling}, реализованное первоначально в качестве интегрированной части Windows NT и позволяющее работать с процессорными исключениями.
Оператор throw
Исключения могут генерироваться или, как принято говорить в C++, выбрасываться либо исполнительной системой C++, стандартными функциями и т. д., либо самим программистом с помощью оператора throw. Он состоит из ключевого слова throw, за которым следует необязательное выражение.
Throw с операндом
Выражение, следующее за ключевым словом throw, можно рассматривать как фактический параметр (аргумент) в вызове функции, хотя здесь круглые скобки не обязательны. Обычно это константа или переменная, тип которой может быть любым, как встроенным, так и пользовательским. Тип операнда определяет обработчик, который будет вызван при исполнении оператора throw. На данный момент мы уже знаем достаточно, чтобы посмотреть законченный пример.
Листинг 12.1. Программа, демонстрирующая простейшие исключения
////////////////////////////////////////////////////////////////////
// SimpTypes.срр: Перехват простых исключений.
//
#include <iostream.h>
#pragma hdrstop
#include <condefs.h>
int main () (
double d = 1.0;
for (int i=0; i<4; i++) { . try {
cout << endl<< "Entering the try-block..." <<end1;
switch (i) { case 0:
throw "Throwing an exception of char*"; // Выбросить
// строку. case 1:
throw 5; // Выбросить
// целое.
default:
throw d; // Выбросить double. }
// Следующий оператор исполняться не будет
// из-за исключений.
cout<< "In the „try-block after all exceptions..." << endl;
} // Конец try-блока.
catch(int 1) { // Обработчик int.
cout << "Int thrown: " << 1 << endl;
} catch(char* str) { // Обработчик char*.
cout << "String thrown: " << str << endl;
} catch (...) { // Для всего остального.
cout << "An unknown type thrown."<< "Program will.terminate." << endl;
cin.ignore () ;
return -1; // Завершить программу. }
cout<< "End of the loop."<< endl;
} // Конец цикла.
cout << "The End." << endl; // Эти операторы не исполняются cin.ignore (); // никогда, т.к. третье
// исключение
return 0; // завершает программу. }
Вывод программы показан на рис. 12.1
Давайте разберемся, что здесь происходит.
В программе организован цикл, который должен выполниться четыре раза. В нем находится пробный блок, генерирующий исключения различных типов — int, char* и double в зависимости от значения счетчика цикла. На первом проходе оператор throw выбрасывает строку, которая перехватывается вторым по счету обработчиком. Так как обработчик не выполняет никаких действий, кроме вывода сообщения, выполнение про-
Рис. 12.1 Простая программа с исключениями
граммы продолжается с оператора, следующего за списком обработчиков. Цикл продолжается, и при втором входе в пробный блок выбрасывается тип int, перехватываемый первым обработчиком.
На третьем проходе цикла выбрасывается переменная типа double, для которого обработчика не предусмотрено. Однако имеется “всеядный” третий обработчик. Он исполняет оператор return, завершающий программу. Поэтому цикл for в четвертый раз не выполняется и вообще программа не доходит до своего “нормального” конца.
Обратите внимание, что последний оператор пробного блока (вывод сообщения) не будет выполняться никогда, так как мы в любом случае выбрасываем исключение в предшествующем ему блоке switch.
Порядок следования catch-обработчиков
Выше мы сказали, что при генерировании исключения ищется обработчик для типа, совпадающего или совместимого с типом исключения. Тут нужна некоторая осторожность. Совместимость в донном случае означает, что:
либо тип выброшенного объекта совпадает с типом, ожидаемым обработчиком (если выброшен объект типа Т, то годятся обработчики для Т, const Т, Т& или const T&); ,
либо тип обработчика является открытым базовым классом для типа объекта;
либо типы обработчика и выброшенного объекта являются указателями, второй из которых может быть приведен к первому согласно общим правилам преобразования указателей.
Процедура поиска не ищет “наилучшего соответствия” типов, а просто берет первый по порядку следования подходящий обработчик. Например, у вас есть два класса исключения, причем второй является производным от первого. Если в списке обработчиков первым будет стоять тот, что предназначен для исключений базового класса, он будет перехватывать все исключения — как базового, так и производного классов. Или рассмотрите такой пример:
int main() {
try {
throw "Throwing char*"; // Выбрасывает char*. }
catch(void*) ( // Ловит void*.
cout<< "Void* caught." << endl;
return -1;
}
catch(char*) { // Ловит char*.
cout << "Char* caught." << endl;
return -1;
}
return 0;
}
Здесь обработчики исключений расположены в неправильном порядке, так как обработчик для void* будет перехватывать все исключения, предназначенные для обработчика char*.
Throw без операнда
Если в операторе throw не указан операнд, то обрабатываемое в данный момент исключение перебрасывается, т. е. поиск подходящих обработчиков будет продолжен далее. Сказанное означает, что такой оператор может применяться только в catch-обработчике или функции, вызываемой из некоторого обработчика.
Основные синтаксические конструкции
Общий синтаксис обработки исключения в C++ такой:
try { // Начало "пробного блока".
throw выражение; / / "Выбрасывание" исключения.
} catch(тип переменная) { // Заголовок обработчика для <типа>.
тело_обработчика) [catch ...] // Возможно, обработчики других типов.
Теперь мы в деталях рассмотрим элементы этой конструкции.
Поиск обработчика и неуправляемые исключения
Если не удается найти подходящий обработчик исключения в списке текущего пробного блока, происходит переход на более высокий уровень, т. е. к списку обработчиков try-блока, -непосредственно включающего текущий. Если такой, конечно, имеется.
Если обработчика для данного исключения в программе не находится вообще, оно считается неуправляемым. В этом случае вызывается функция terminate () . Она, в свою очередь, вызывает функцию abort () , которая аварийно завершает программу.
Можно установить свою собственную процедуру завершения с помощью функции set_terminate () ; прототип ее находится в except, h:
typedef void(_RTLENTRY *terminate_function) ();
terminate_function _RTLENTRY set_terminate(terminate function);
Как и другие подобные функции, она возвращает адрес предыдущей процедуры завершения. Процедура завершения не может ни возвратить управление, ни выбросить исключение.
Следующая программа демонстрирует некоторые моменты вышесказанного. Ее вывод показан на рис. 12.2.
Листинг 12.3. Поиск обработчиков и неуправляемые исключения
///////////////////////////////////////////////////////////
//Unhandled. срр: Прохдедура для неуправляемых исключений.
//
#include <iostream.h>
#include <except.h>
#pragma hdrstop
#include <condefs.h>
class Dummy {}; // Пустой класс исключения.
void FuncB(int f) {
if (!f) { cout << "FuncB: throwing int..." << endl;
throw 7;
} else {
cout<< "FuncB: throwing char*..."<< endl;
throw "Exception!";
} }
void FuncA(int f)
{
try {
FuncB(f);
} catch(char* str) { // Обработчик выбрасывает Dummy.
cout << "FuncA: char* caught. Rethrowing Dummy..."<< endl;
Dummy d;
throw d;
} }
void MyTerminate() // Новая процедура завершения. {
cout << "Termination handler called..." << endl;
abort ();
}
int main() {
set_terminate(MyTerminate); // Установка процедуры
// завершения.
for (int j=0; j<2; j++) { try {
FuncA(j) ;
} catch(int k) {
cout << "Main: int caught - " << k << endl;
} }
// Следующие операторы исполняться не будут... cout “ "Exiting main..." “ endl;
return 0;
}
Рис.12.2 Выполнение программы Unhandled
Тело пробного блока в main () выполняется два раза. Имеется вложенный пробный блок в FuncA () . На первом проходе FuncB () выбрасывает int, для которого нет обработчика во внутреннем блоке и потому перехватываемое во внешнем пробном блоке, т. е. в main О . На втором проходе выбрасывается строка, которая перехватывается в FuncA () . Обработчик сам выбрасывает исключение Dummy — неуправляемое, поэтому вызывается установленная пользователем процедура завершения.
Предопределенные исключения
В библиотеке C++ имеется несколько предопределенных классов исключений. В следующих параграфах мы рассмотрим некоторые из них.
xmsg
Класс xmsg предназначен для передачи строковых сообщений об исключениях. Он объявлен в заголовке except, h:
class EXPCLASS xmsg : public std::exception
{ public:
xmsg(const std::string &msg);
xmsg(const xmsg &);
virtual ~xmsg() throw ();
xmsg & operator=(const xmsg &) ;
virtual const char * what() const throw ();
const std::string & why() const;
void raise () throw(xmsg);
private:
std::string *str;
};
Применять класс xmsg очень просто:
#include <iostream.h>
#include <except.h>
#pragma hdrstop
#include <condefs.h>
int main() {
try {
xmsg X("Exception!");
throw X;
// или
//
X.raise () ;
}
catch(xmsg Smsg) {
cout << "Caught in main: " << msg.why() << end1;
}
return 0;
}
В классе имеется функция-элемент raise (), посредством которой объект выбрасывает сам себя. Ею можно воспользоваться вместо оператора throw. Функция why () возвращает стандартную строку с сообщением, записанным в объект.
Класс xmsg считается устаревшим. Теперь в стандартной библиотеке C++ определяется ряд классов (производных от exception, как и xmsg), организованных иерархически. По сути они ничем друг от друга не отличаются; данные им имена ничего особенного не значат. Вот эти классы: class logic_error public exception class domain_error public logic_error class invalid argument public logic_error class length_error public logic_error class out_of_range public logic_error class runtime error public exception class range error public runtime error class overflow_error public runtime error class underflow error public runtime error
Как видите, logic_error и runtime_error — производные от exception, а все остальные — от первых двух. Эти классы имеют конструктор, принимающий ссылку на стандартную строку, виртуальный деструктор и виртуальную функцию-элемент what (), которая возвращает указатель на константную строку С. Вот пример:
#include <iostream>
#include <stdexcept>
using namespace std;
static void f() ( throw runtime_error("a runtime error");
}
int main ()
{
try
{ f();
}
catch (const exceptions e) {
cout << "Got an exception: " << e.what() << endl;
} return 0;
}
Программа печатает:
Got an exception: a runtime error
Иерархия и полиморфизм этих классов делают их весьма гибким средством организации обработки ошибок.
bad_alloc
Если операция new не может выделить запрашиваемую память, она выбрасывает исключение bad_alloc. Этот класс также является производным от exception:
class bad alloc : public exception {
public:
bad_alloc () throw() : exception () { ; }
bad_alloc(const bad_alioc&) throw()
{ ; }
bad_alloc& operator=(const bad_alloc&) throw()
{ return *this; }
virtual ~bad_alloc () throw ();
virtual const char * what () const throw()
{
return _RWSTD::_rw_stdexcept_BadAilocException;
} };
Продемонстрировать реальную работу этого класса с реальной операцией new вряд ли возможно, да и не стоит. Можно, однако, выбросить bad_alloc вручную:
int main () {
try {
throw bad_alloc();
} catch(const exception &e) (
cout << "Caught something: "<< e.what() “ endl;
}
return 0;
}
Функция what () объекта bad_alloc возвращает строку "bad alloc exception thrown".
В прежних версиях языка new при ошибке выбрасывала xalloc, класс, производный от xmsg:
class _EXPCLASS xalloc : public xmsg
{
public:
xalloc(const std::string &msg, _SIZE_T size);
_SIZE_T requested () const.;
void raise () throw(xalloc);
private:
_SIZE_T siz;
};
Теперь этим классом пользоваться нельзя, и он остался в библиотеке C++Builder только для обеспечения совместимости со старыми библиотеками. Еще раньше операция new при отказе просто возвращала NULL. Такое поведение операции восстановить очень просто, вызвав функцию set_new_hand-ler():
#include <new.h>
set new handler (0);
Прототип set_new_handler () имеет вид
typedef void (*new_handler)();
new_handler set__new_handler(new_handler rny_handler);
Функция предназначена для установки пользовательского обработчика ошибок глобальных операций new или new [ ]. Обработчик my handler может:
освободить память (удалить какой-то мусор) и возвратить управление;
вызвать функцию abort () или exit ();
выбросить исключение bad_alloc или производного типа.
В идеале обработчик освобождает ненужную память и возвращает управление. В этом случае new снова попытается удовлетворить запрос.
В следующей главе мы встретимся еще с двумя предопределенными классами исключений — bad_typeid и bad_ typeinfo.
Процессорные исключения
Наибольший интерес для нас представляют исключения, связанные с процессором. Их, как уже говорилось, нельзя обрабатывать стандартными средствами C++. Для этих исключений в заголовке winbase.h определен ряд символических констант. Вот некоторые из них:
EXCEPTION_ACCESS_VIOLATION
EXCEPTION_ARRAY_BOUNDS_EXCEEDED
EXCEPTION_FLT_DENORMAL_OPERAND
EXCEPTION_FLT_DIVIDE_BY_ZERO
EXCEPTION_FLT_INEXACT_RESULT
EXCEPTION_FLT_INVALID_OPERATION
EXCEPTION_FLT_OVERFLOW
EXCEPTION_FLT_STACK_CHECK
EXCEPTION_FLT_UNDERFLOW
EXCEPTION_INT_DIVIDE_BY_ZERO
EXCEPTION_INT_OVERFLOW
EXCEPTION_PRIV_INSTRUCTION
EXCEPT ION_IN_PAGE_ERROR
EXCEPTION_ILLEGAL_INSTRUCTION
EXCEPTION_NONCONTINUABLE_EXCEPTION
EXCEPTION_STACK_OVERFLOW
EXCEPTION_INVALID_DISPOSITION
EXCEPTION_GUARD_PAGE
Ниже показан пример, в котором имитируется нарушение доступа путем разыменования нулевого указателя. Функция фильтра детектирует эту ошибку, и обработчик исключения выводит соответствующее собщение:
///////////////////////////////////////////////////
// Access.cpp: Применение SEH для перехвата
// системных исключений.
//
#include <except.h>
#include <iostream.h>
#pragma hdrstop
#include <condefs.h>
static int xfilter(EXCEPTION_POINTERS *info)
{
if (info->ExceptionRecord->ExceptionCode == EXCEPTION_ACCESS_VIOLATION)
return EXCEPTION_EXECUTE_HANDLER;
else
return EXCEPTION_CONTINUE_SEARCH;
}
int main () {
try (
int *p = NULL;
*P = -1;
}
_except(xfilter(GetExceptionInformation())) { cerr << "Exception Access Violaton caught..." << endl;
exit(l);
} cout<<"Normal exit..." << endl;
return 0;
}
Для справки приведем описание структуры exception_pointers:
struct EXCEPTION_POINTERS {
EXCEPTION_RECORD *ExceptionRecord;
CONTEXT *Context;
};
Struct EXCEPTION_RECORD { DWORD ExceptionCode;
DWORD ExceptionFlags;
struct EXCEPTION_RECORD *ExceptionRecord;
void *ExceptionAddress;
DWORD NumberParameters;
DWORD ExceptionInformation[EXCEPTION_MAXIMUM_PARAMETERS];
Как уже говорилось, структуры управления исключениями SEH и C++ могут быть вложены друг в друга. Более того, except-обработчик может выбрасывать исключение C++, которое будет далее перехватываться catch-обработчиком. Можно в целях удобства и единообразия заключить все критические участки кода, могущие возбудить процессорные исключения (или вообще всю программу) в блоки try/ except, выбрасывающие исключения C++, и затем обрабатывать их наравне с другими исключениями. Рассмотрите такой пример:
////////////////////////////////////////////////
// SehPlus.cpp: Переход от SEH к C++.
//
#include <iostream.h>
#include <excpt.h>
#include <stdexcept>
#pragma hdrstop
#include <condefs.h>
static EXCEPTIONJRECORD eRec;
static int xfliter(EXCEPTION_POINTERS *xp) {
eRec = *(xp->ExceptionRecord);
return EXCEPTION_EXECUTE_HANDLER;
}
int main () {
double d = 10000;
try { try {
for (int i=5; i>=0; i-) { d = d / i;
cout << i << "... ";
} }
_except- ixfliter(GetExceptionInformation ())) ( if (eRec.ExceptionCode ==
EXCEPTIOM_FLT_DIVIDE_BY_ZERO) throw runtime error(
"Floating point divide by zero!");
else
throw runtime_error(
"Unknown processor exception.");
} }
catch(const exception &e) { cout << e.what() << end1;
} return 0;
}
Программа выводит:
5... 4... 3...2... I... Floating point divide by zero!
Целесообразно было бы предусмотреть для процессорных исключений специальный класс, производный от, например, runtime_error, дополнив его структурой EXCEPTION RECORD. Тогда вообще вся обработка осуществлялась бы средствами C++.
Заключение
В этой главе вы познакомились со средствами C++, позволяющими сделать обработку ошибок и других исключительных ситуаций гораздо более единообразной и надежной, чем это было возможно когда-либо прежде. Кроме того, исключения используются стандартными библиотеками и в самом языке (класс string, операция new). Поэтому я всячески призываю вас практиковаться и привыкать к управлению исключениями.
SEH в C++
Как вы, возможно, помните, в языке С (расширенном) имеются две структуры управления исключениями. Это обработка кадра (__try/_except) и обработка завершения (_try/_finally).
Обработки завершения мы здесь касаться не будем и вообще не будем в подробностях рассматривать работу со структурированными исключениями в C++, поскольку нас прежде всего интересуют здесь системные исключения, не поддерживаемые стандартным C++. Вместо ключевого слова _try в коде C++ принято писать просто try, как и для встроенных исключений языка. Таким образом, мы будем пользоваться только конструкцией try/_except.
Итак, синтаксис кадровой структуры управления имеет вид:
try
{
<тело защищенного блока> }
_except(<выражение-фильтр>) {
<блок обработки кадра>. }
В программе можно одновременно использовать управление исключениями C++ и кадрированную обработку исключений. Их структуры могут быть вложенными.
Фильтры
Фильтрующее выражение должно принимать одно из трех значений:
EXCEPTION_EXECUTE_HANDLER
EXCEPTION_CONTINUE_SEARCH
EXCEPTION_CONTINUE_EXECUTION
Они соответствуют исполнению данного обработчика, продолжению поиска (стек разматывается, и поиск обработчика переходит на более высокий уровень) и продолжению выполнения программы с той точки, где было возбуждено исключение.
В выражении фильтра можно вызвать функцию GetExceptionInformation() или GetExceptionCode () . Первая из них возвращает указатель на структуру EXCEPTION_POINTERS, которая содержит детальную ин-
формацию об исключении; вторая возвращает только кодовое значение для исключения. Чаще всего в качестве выражения фильтра используют функцию, аргументом которой является значение, возвращаемое одной из этих двух функций.
Сама функция фильтра не может вызывать GetExceptionInformation () или GetExceptionCode (). Значения, возвращаемые этими функциями, должны передаваться ей в аргументах.
Точно так же и блок обработчика не может вызывать данные функции. Функция фильтра должна скопировать необходимую информацию в такое место, где она будет доступна для обработчика исключения.
Вот пример простейшей функции фильтра:
int MyFilter(int code) {
if (code == EXCEPTION_ACCESS_VIOLATION) return EXCEPTION_EXECUTE_HANDLER;
else
return EXCEPTION_CONTINUE_SEARCH;
}
try {
}
_except(MyFilter(GetExceptionCode())) {
}
Спецификации исключений.
В определении функции можно указать, исключения какого типа она может выбрасывать. Спецификация исключений для функции выглядит так:
<тип> FuncName(<список параметров>) throw([<тип>
[, <тип> ...]])
{
<тело функции>
}
Тем самым мы сообщается, что функция может выбрасывать только типы, перечисленные в списке после ключевого слова throw. Если этот список пустой, то функция вообще не должна выбрасывать никаких исключений.
Обработка непредвиденных исключений
Однако то, какие исключения функция прямо или косвенно выбрасывает на самом деле, выясняется только во время выполнения. Компилятор не выдает никаких ошибок или предупреждений на этот счет. Если функция, снабженная спецификацией исключений, выбрасывает непредвиденное, т. е. не указанное в спецификации, исключение, вызывается функция unexpected () . По умолчанию последняя просто вызывает terminate () . Вы можете, тем не менее, указать свою собственную функцию, которая должна активироваться при появлении непредвиденных исключений, вызвав set_unexpected (). Прототип ее находится в файле except.h (не обращайте внимания на _RTLENTRY; он расширяется в _cdecl):
typedef void (_RTLENTRY *unexpected_function)();
…
unexpected_function _RTLENTRY set_unexpected(unexpected_function);
Возвращается указатель на предыдущую функцию обработки. Процедура для непредвиденных исключений не должна возвращать управление. Она может либо аварийно завершить программу, либо выбросить исключение.
Управление исключениями
Грамотно организованная, устойчивая программа должна справляться с нестандартными ситуациями, встречающимися в реальной работе с реальными данными. Такой нестандартной ситуацией может быть, например, ошибка пользователя при вводе данных или нарушение структуры некоторого файла. В языках, предшествующих C++, подобные проблемы решались с помощью глобальных “флагов ошибки” или приписыванием определенному значению, возвращаемому функцией, специального смысла “индикатора ошибки”. Язык C++ вводит понятие управления исключениями, т. е. специальных средств изменения программного потока управления с целью обработки нестандартных, непредвиденных или ошибочных ситуаций, возникающих в процессе работы.
В главе 4 мы вкратце упоминали о т. н. структурированной обработке исключений (SEH) в языке С; она реализуется в C++ Builder при посредстве нестандартных ключевых слов _try, _except и _finally. Ее принципы заимствованы, на самом деле, из операционной системы Windows NT; в NT это средства, встроенные в систему.
В C++ средства обработки исключений встроены непосредственно в язык. Ключевые слова, связанные с данным аспектом языка, следующие: try, catch и throw.
Из достоинств обработки ошибок с использованием исключений, по сравнению с традиционными методами, можно назвать следующие:
устранение глобальных переменных;
увеличение возможностей отладки благодаря тому, что исключения являются составной частью языка;
невозможность игнорирования ошибок и продолжения программы так, как будто бы ничего не случилось.
Недостаток обработки исключений состоит, на наш взгляд, в том, что приходится вводить дополнительные уровни операторных скобок; код делается более громоздким. Но это в любом случае с лихвой компенсируется ее достоинствами.
Следует заметить, что, в отличие от модели SEH, при генерировании исключения в C++ невозможно продолжить выполнение программы с того самого места, где оно возникло.
Установки компилятора
Помимо упоминавшегося выше флажка Location information, в группе Exception handling страницы C++ диалога установок проекта находятся следующие флажки:
Enable exceptions — при сброшенном флажке исключения запрещены, и компилятор генерирует сообщение об ошибке, если встречает try-блок; соответствует ключу командной строки -х и по умолчанию установлен.
Destructor cleanup — если установлен, то при разматывании стека вызываются деструкторы локальных автоматических объектов; по умолчанию установлен. Соответствующий ключ командной строки — -xd.
Fast exception prolog — при установленном флажке ряд служебных функций, ответственных за обработку исключений, расширяются как inline; по умолчанию сброшен. Ключ командной строки -xf.
