Абстракция через параметризацию
Абстракция через параметризацию позволяет, используя параметры, представить фактически неограниченный набор различных вычислений одной программой, которая есть абстракция этих наборов.
Абстракцией через параметризацию почти все Вы пользовались много раз, даже не замечая этого. Возьмем наш пример с поиском максимального значения в массиве. Использовав эту процедуру однажды, вероятно, где-то в другом месте программы необходимо будет найти максимальный элемент в другом массиве, причем его имя может быть вовсе не а, а скажем z.
int aMax, a[100];
int zMax, z[100];
:
aMax = GetMaxValue (a);
:
zMaz = GetMaxValue (z);
Следовательно, мы используем абстракцию через параметризацию, обобщая этим процедуру и делая ее более универсальной.
Абстракция через параметризацию - весьма полезное средство. Она не только позволяет проще описывать большое число вычислений, но и, как правило, легко реализуема. Однако она не позволяет полностью реализовать тот уровень обобщения, который можно достичь при работе с процедурами.
Абстракция через спецификацию
Абстракция через спецификацию позволяет абстрагироваться от процесса вычислений описанных в теле процедуры, до уровня знания того, что данная процедура делает. Это достигается путем задания спецификации, описывающей эффект ее работы, после чего смысл обращения к данной процедуре становится ясным через анализ этой спецификации, а не самого тела процедуры. Мы пользуемся абстракцией через спецификацию всякий раз, когда связываем с процедурой некий комментарий, достаточно информативный для того, чтобы иметь возможность работать без анализа тела процедуры.
Спецификации важны для достижения требуемой модульности программы. Абстракция используется для декомпозиции программы на модули. Однако взятая в отдельности абстракция является малопонятной. Без какого-либо описания мы не можем ни сказать, что она собой представляет, ни отличить ее от одной из своих реализаций. В качестве такого описания и выступает спецификация.
Спецификация описывает соглашение между разработчиками и пользователями. Разработчик берется написать модуль, а пользователь соглашается не полагаться на знания о том, как именно этот модуль реализован, т.е. не предполагать ничего такого, что не было бы указано в спецификации. Такое соглашение позволяет разделить анализ реализации от собственно использования программы. Спецификации дают возможность создавать логические основы, позволяющие успешно "разделять и властвовать".
При анализе спецификации для уяснения смысла обращения к процедуре нужно придерживаться двух правил:
1. После выполнения процедуры можно считать, что выполнено конечное условие. Выполнение конечного условия при соблюдении начальных условий - это собственно то, ради чего и построена процедура. Если это процедура поиска максимального значения в массиве, то конечное условие - факт, что максимальный элемент найден. Если это процедура вычисления квадратного корня, то конечное условие - нахождение квадратного корня.
2. Можно ограничиться только той информацией, которую подразумевает конечное условие.
Эти правила демонстрируют два преимущества абстракции через спецификацию. Первое состоит в том, что программисты, использующие данную процедуру, не обязаны знакомиться с ее телом. Следовательно, им не нужно уяснять, например, подробности алгоритма отыскания квадратного корня, устанавливая действительно ли возвращенный результат искомое число.
Второе правило показывает, что на самом деле имеем дело с абстракцией: абстрагируясь от тела процедуры, можно не обращать внимания на несущественную информацию. Именно такое "игнорирование" информации и отличает абстракцию от декомпозиции. Конечно, анализируя тело процедуры можно извлечь некоторое количество информации, не следующей из конечного условия (как, например, то, что найденный элемент первый или последний в рассмотренном выше примере). В спецификации подобная информация о возвращаемом результате отбрасывается.
Абстракции через параметризацию и через спецификацию являются мощным средством для создания программ. Они позволяют определить два вида абстракций: процедурную абстракцию и абстракцию данных. В общем случае каждая процедурная абстракция и абстракция данных используют оба способа.
Например, абстракцию SQRT (извлечение квадратного корня) можно сравнить с операцией: она абстрагирует отдельное событие или задачу. Мы будем ссылаться к абстракциям такого рода как к процедурным абстракциям. Отметим, что абстракция SQRT включает в себя как абстракцию через параметризацию, так и абстракцию через спецификацию. Процедурная абстракция - мощное средство. Она позволяет расширить заданную некоторым языком программирования виртуальную машину новой операцией. Такое расширение полезно, когда мы работаем с задачами, которые можно представить в виде набора независимых функциональных единиц. Однако часто удобно к такой новой виртуальной машине добавить несколько объектов данных с новыми типами.
Поведение объектов данных наиболее естественно представлять в терминах набора операций, применимых к данным объектам. Такой набор включает в себя операции по созданию объектов, получению информации о них и их модификации.
Например, при работе с целыми числами используются обычные арифметические операции, но при работе со стеком нужны другие операции, такие как POP (изъять из стека), PUSH (положить в стек).
Таким образом, абстракция данных (или тип данных) состоит из набора объектов и набора операций, характеризующих поведение этих объектов.
Абстракция данных
То, какие новые типы данных необходимы, зависит от области применения программы. При реализации интерпретатора полезны стеки, а при определении пакета численных функций - матрицы, в банковской системе естественной абстракцией являются счета. В каждом конкретном случае абстракция данных состоит из набора объектов (стеков, полиномов, матриц и т.д.) и набора операций над ними. Например, матричные операции включают в себя сложение, умножение...
Новые типы данных должны включать в себя абстракции как через параметризацию, так и через спецификацию. Абстракция через параметризацию может быть осуществлена также как и для процедур, - использованием параметров там, где это имеет смысл. Абстракция через спецификацию достигается за счет того, что мы представляем операции как часть типа. Чтобы понять зачем, почему необходимы операции, посмотрим, что получится, если рассматривать тип просто как набор объектов. В этом случае, все, что необходимо сделать для реализации типа - это выбрать представление памяти для объектов. Тогда все программы могут быть реализованы в терминах этого представления. Однако, если представление изменяется, все программы, которые используют этот тип, должны быть изменены.
С другой стороны, предположим, что операции включены в определение типа следующим образом:
абстракция данных = <объекты, операции>
При этом потребуем, чтобы пользователи употребляли эти операции непосредственно, не обращаясь к представлению. Затем для реализации типа мы реализуем операции в терминах выбранного представления. При изменении представления нужно заново реализовывать только операции. Однако переделывать программы уже нет необходимости, так как они не зависят от представления, а зависят только от операций. Следовательно, мы получаем абстракцию через спецификацию.
Если обеспечено большое количество операций, отсутствие прямого доступа к представлению не будет создавать для пользователя трудностей, все что они хотят сделать с объектами, может быть сделано при помощи операций. Обычно имеются операции для создания и модификации объектов, а так же для получения информации об их значениях. Пользователи могут увеличивать набор операций определением процедур, но такие процедуры не должны использовать представление.
Абстракция данных - наиболее важный метод в проектировании программ. Выбор правильных структур данных играет решающую роль для создания эффективных программ. При отсутствии абстракций данных структуры данных должны быть определены до начала реализации модулей. Абстракция же данных позволяет отложить окончательный выбор структур данных до момента, когда эти структуры станут вполне ясны. Вместо того чтобы определять структуру непосредственно, мы вводим абстрактный тип со своими объектами и операциями. Затем можно осуществлять реализацию модулей в терминах этого абстрактного типа, решение же о конкретной реализации типа может быть принято позже, когда использование данных станет вполне понятным.
Абстракции данных полезны при модификации программ, когда предпочтительнее изменить структуру данных в реализации типа, не меняя при этом самой программы.
Для реализации типа данных мы выбираем представление для объектов и реализуем операции в терминах этого представления. Выбранное представление должно предоставлять возможности для довольно простой и эффективной реализации всех операций. Кроме того, если некоторые операции должны выполняться быстро, представление должно предоставлять и эту возможность. Заметим, что, вообще говоря, следует различать новый абстрактный тип и тип его представления. Предполагается, что с типом представления мы имеем дело только при реализации. Все, что мы можем делать с объектами абстрактного типа, - это применять к ним соответствующие данному типу операции.
Если абстракция данных определена, то она не отличается от встроенных типов и ее объекты и операции должны использоваться точно также как объекты и операции встроенных типов. Определенные пользователем типы могут также использоваться для представления других определяемых пользователем типов.
Теперь, когда мы немного уяснили, что же такое операции над абстрактными типами данных, дадим им некоторую классификацию.
Абстрактный класс
Иногда, когда виртуальная функция объявляется в базовом классе, она не выполняет никаких значимых действий. Это вполне обычная ситуация, поскольку часто базовый класс не определяет законченный тип, или, если рассматривать наш пример, объект базового типа не представляет особой ценности. Речь здесь идет о том, что хотя базовый класс (Point) и содержит базовый набор методов и состояний, который производный класс дополняет всем недостающим, полезность точки, как графического объекта, не велика и, программируя, например, некоторый графический интерфейс, без точки, как объекта, можно вполне обойтись. Однако мы выяснили, что именно Point, как нельзя лучше подходит для роли базового класса, поскольку Point содержит в себе главные атрибуты любых графических объектов. Т.е. мы пришли к пониманию того, что класс Point ценен не своими объектами, а своей способностью выступать в качестве базового класса.
Возвращаясь к виртуальным методам, заметим, что теперь, когда отпала необходимость создавать объекты класса Point, методы виртуальные Show() и Hide() стали нужны только для того, чтобы их обязательно переопределили в производных классах. Для реализации этого положения С++ поддерживает чисто виртуальные методы.
Чисто виртуальные методы не определяются в базовом классе. У них нет тела, а есть только декларации об их существовании.
Для чисто виртуальной функции используется общая форма
virtual тип имя_функции (список параметров) = 0;
Ключевой частью этого объявления является приравнивание функции к нулю.
Класс, содержащий хотя бы один виртуальный метод, называется абстрактным классом. Абстрактные классы не бывают изолированными, т.е. всегда абстрактный класс должен быть наследуемым. Поскольку у чисто виртуального метода нет тела, то создать объект абстрактного класса невозможно.
Абстрактным классом можно назвать класс, специально определенный для обеспечения наследования характеристик порожденными классами.
Вот как теперь станет выглядеть наш новый Point.
class Point
{
protected:
int X;
int Y;
Boolean Visible;
public:
int GetX(void) { return X; }
int GetY(void) { return Y; }
Boolean isVisible (){ return Visible;}
Point (int newX =0, int new Y =0);
virtual void Show() = 0; // чисто виртуальная функция
virtual void Hide() = 0; // чисто виртуальная функция
void MoveTo (int newX, int newY)
{
Hide();
X = newX; Y = newY;
Show();
}
};
Класс Point теперь действует как заготовка, из которого все порожденные классы могут взять элементы, общие для всех типов в иерархии, но теперь, при попытке создать объект типа Point, компилятор выдаст сообщение об ошибке.
Заметьте, что необходимость конструктора при этом не отпала, поскольку по-прежнему нужно будет инициализировать X, Y и Visible для производных классов.
Приведенное выше логическое обоснование или разумное объяснение демонстрирует важный принцип ООП: определяя иерархию классов, соберите все общие атрибуты в один абстрактный класс, и определите иерархию классов так, чтобы все общие элементы использовались из этого класса.
| [назад] | [оглавление] | [вперед] |
Базовые типы
Целый (integer). Представляет множество целых чисел. В системе программирования должны быть определены следующие операторы:
+ сложение,
- вычитание,
* умножение,
/ деление,
% остаток от целочисленного деления.
В каждой ВМ определено некоторое подмножество целых чисел, лежащих в некоторых пределах. С этим подмножеством компьютер может оперировать прямо и эффективно.
Следует отметить, что, несмотря на внешнюю простоту целого типа, обычные аксиомы арифметики, вообще говоря, нельзя применять к арифметике вычислительной машины. Они не верны в тех случаях, когда истинный результат операции лежит вне заданного конечного диапазона значений.
Например, если для некоторой вычислительной системы тип int определен как множество целых чисел, по абсолютной величине не превосходящих max (|x| <= max), и если сложение, выполняемое машиной, обозначить как add, то
x add y = x + y
только тогда, когда |x + y| <= max. Следовательно, обычный ассоциативный закон, вообще говоря, для машины не выполняется.
Соотношение
(x add y) add z = x add (y add z)
верно тогда, когда |x add y| <= max и |y add z| <= max.
Например, положим max = 100 и подставим значения x = 60, y = 50 и z = -40. Тогда
60 add (50 add (-40)) = 70
а результат (60 add 50) add (-40) не определен.
Количество элементов памяти, необходимое для хранения значений переменной в машине, зависит от диапазона значений, которые эта переменная может принимать. Например, если переменная должна принимать n различных значений, то для ее хранения потребуется log2(n) битов. Я напоминаю Вам этот, конечно же, известный факт по той только причине, что мы привыкли исходить из обратного - то есть, от машинного представления данного типа. Чаще мы рассуждаем так: для хранения переменной целого типа отводится 16 бит. Следовательно, самое большое целое число (то есть граница интервала) есть 65535 (216 - 1). Хотя надо оценивать интервал значений, необходимый нам для моделирования, и под него выбирать тип переменной.
Литерный (char). Этот тип обозначает конечное упорядоченное множество литер. Помимо диапазонов чисел, следует определять набор литер, с помощью которых компьютер общается с внешним миром. Литерами из этого набора снабжаются все периферийные устройства (читающие и печатающие). Существует несколько общепринятых стандартов наборов литер:
Международной организации стандартов ISO - International Standards Organisation;
Американский стандартный код для обмена информацией ASCII - American Standard Code for Information Interchange
8-ми и 7-ми битовые коды обмена информацией КОИ-8 и КОИ-7
Наиболее популярный ASCII код поддерживает 26 букв латинского алфавита, 10 десятичных арабских цифр, некоторое количество специальных литер, таких, как знаки пунктуации. Стандарт определяет 128 литер, подразделяющихся на печатаемые и управляющие. Управляющие литеры играют большую роль при передаче данных. Например, литеры Carriage Return и Line Feed обрабатываются всеми построчно печатающими устройствами. Оставшиеся 128 кодов от 128 до 255 могут определять коды национального языка. Существуют четыре варианта кодировки символов кириллицы. Стандартом de facto стал так называемый альтернативный вариант кодировки. Сейчас, когда отечественная промышленность перестала производить ЭВМ, проблемы нескольких стандартов стали не такими острыми. Хотя еще попадаются файлы с документацией, набранные в основном варианте кодировки. Тогда мы видим по преимуществу, не буквы, а символы псевдографики. А всего лишь несколько лет назад выпускаемые различными министерствами ПЭВМ (скопированные с одного и того же образца IBM PC XT) имели различные кодировки.
Отображение битов на множество литер называется кодом. Следовательно, каждой литере соответствует целое неотрицательной число. Таким образом, тип char можно интерпретировать как множество неотрицательных целых чисел в интервале от 0 до 255, или множество целых чисел в интервале от -128 до +127. Некоторые языки имеют функции преобразования из целого числа в литерное и наоборот (например, BASIC).
Лирическое отступление UNICODE.
Хорошо, когда национальная письменность соотносится с набором литер латинского алфавита. Например, на 26 латинских литер - 33 литеры кириллицы. А каково арабам, китайцам, японцам? Клинопись, иероглифы и языки, в которых столько букв, что одного байта для кодировки не хватает. Для поддержки подобных языков были созданы двухбайтовые наборы символов. Как всегда, было предложено несколько вариантов, и после непродолжительных мучений был выработан стандарт Unicode. Его первоначально разработали фирмы Apple и Xerox в 1988 году. В 1991г был создан консорциум, в который вошли основные производители Hardware и Software. Строки в Unicode просты и логичны. Все символы в них состоят из 16-битовых кодов. Следовательно. Можно закодировать 65536 символов. Этого достаточно даже для японской каны. В настоящее время кодовые позиции определены для нескольких языков и задействовано около 34000 кодов. Так что место для расширения есть. Кодовые позиции разбиты на группы:
0000 - 007F ASCII
0080 - 00FF Расширение ASCII (Latin 1)
0100 - 017F Европейские латинские
0180 - 01FF Расширенные латинские
0250 - 02AF Стандартные фонетические
02B0 - 02FF Модифицированные литеры
0300 - 03FF Общие диакритические знаки
0370 - 03FF Греческий
0400 - 04FF Кириллица
0530 - 058F Армянский
0590 - 05FF Еврейский
0600 - 06FF Арабский
0900 - 097F Деванагари
Около 29000 кодовых позиций пока не занято, но зарезервировано для будущего использования. Приблизительно 6000 позиций оставлено специально для программистов.
Вещественный (real, float, double :) Особое значение имеет тот факт, что в машине можно представить только значения из конечного диапазона. В случае целых чисел можно утверждать, что при любых обстоятельствах, кроме переполнения, в результате выполнения арифметических операций получались точные значения. Но применительно к арифметике с вещественными числами это утверждение неверно.
Причина заключается в том, что на сколь угодно малом интервале оси вещественных чисел содержится бесконечно много значений. Ось вещественных чисел образует так называемый континуум.
В программировании, тип real не представляет бесконечное, несчетное множество вещественных чисел; ему соответствует конечное множество представителей интервалов континуума вещественных чисел.
Результаты вычислений, в которых участвуют приближенные, а не точные значения, в значительной степени зависят от решаемой задачи и от выбранного алгоритма. В лучшем случае полученные результаты будут приближениями с неизбежными погрешностями. Оценка этих погрешностей, которые являются результатом подмены вещественного континуума конечным множеством представителей, является очень трудной задачей и служит объектом изучения вычислительной математики.
Естественно, что производить вычисления, ничего не зная о природе и степени ожидаемой погрешности, бессмысленно. Чтобы понимать и даже проводить такие измерения, необходимо знать, какого вида представления используются для вещественных чисел с конечным числом цифр. В современных компьютерах обычно используют так называемое представление с плавающей точкой (отсюда и пошло название типа float)
Вещественное число x изображается с помощью двух целых чисел e и m, каждое из которых содержит конечное число цифр, так что
x = m * Be, -E < e < E, -M < m < M
Здесь m называется мантиссой, e - порядком, а B, E и M являются константами, характеризующими представление. Число B называется основанием представления с плавающей точкой. Обычно B не равно 10 (как мы привыкли в школьном курсе математики), а является малой степенью 2.
Для любого заданного значения x можно найти много различных пар (m, e). Каноническая или нормализованная форма определяется дополнительным соотношением
(M/B)<=|m|<M
При использовании только нормализованной формы плотность представителей интервалов на оси вещественных чисел экспоненциально уменьшается с увеличением |x|. Например, интервал [0.1:1] содержит приблизительно столько же представителей, сколько интервал [10000 : 100000]. (Для основания представления 10 это точно столько).
Эта неравномерность накладывает ряд ограничений. Очевидно, что нельзя точно описать элементарные операции над аргументами типа float. Поэтому они определяются в виде аксиом:
Тип float является конечным подмножеством множества вещественных чисел
Каждому числу x принадлежащему множеству вещественных чисел ставится в соответствие число типа float, которое называется его представителем.
Каждое число типа float представляет множество вещественных чисел, но это множество значений является связным интервалом на вещественной числовой оси.
Существует максимальное значение max, такое, что для всех |x| > max представители не определены.
Множество чисел типа float симметрично относительно 0.
Следующие аксиомы постулируют совокупность требований, которые безоговорочно должны выполняться в любой машинной арифметике.
Коммутативность сложения и умножения
x + y = y + x, x * y = y * x
x >= y >= 0 (x - y) + y = x
Симметричность основных операций относительно 0
x - y = x + (-y) = - (y - x)
( -x ) * y = x * ( -y ) = - (x * y )
( -x ) / y = x / ( -y ) = - (x / y )
Монотонность основных операций
если 0 <= x <= a и 0 <= y <= b
то x + y <= a + b, x - b <= a - y,
x * y <= a * b/ x / b <= a / y
Обратите внимание, что обычные для арифметики законы ассоциативности и дистрибутивности отсутствуют в рассмотренных аксиомах. Это не случайно. Использование конечного числа представителей может нарушить исполнение этих законов. Например, если наше представление позволяет хранить только 4 цифры (порядок будем задавать положением десятичной точки) то
x = 9.900 y = 1.000 z = -0.999
1. (x + y) + z = 10.90 + (-0.999) = 9.910
2. x + (y + z) = 9.900 + 0.001 = 9.901
Вы можете сами представить подобный пример нарушения дистрибутивного закона.
Определенную опасность представляют операции сложения и вычитания. Они являются причиной значительных ошибок, особенно при вычитании почти равных значений. В этом случае большое количество значащих цифр взаимно уничтожаются, и в полученной разности может не оказаться нескольких, а может быть и всех значащих цифр.
Деление также представляет потенциальную опасность. В случае малых делителей результат легко может оказаться в области переполнения. Поэтому следует избегать деления на числа, близкие к нулю. Например, не следует в программе пользоваться отношением вида abs (t/x) <= eps, его лучше заменить отношением вида abs(t) <= eps * abs(x). Оно не содержит деления.
Мне кажется, что рассмотренные положения несколько поколебали Ваши представление о типах как о чем-то простом и понятном. А ведь мы пока говорили только об основных типах. Пора переходить к составным и производным типам.
Библиотека iostream
Простое внесение.
Выражение извлечения.
Создание собственных функций внесения и извлечения.
Функции библиотеки iostream.
Манипуляторы ввода-вывода.
Файловые и строковые потоки.
Библиотека потокового ввода-вывода iostream может быть использована в качестве альтернативы известной стандартной библиотеки ввода-вывода языка С - stdio. Для нас библиотека iostream интересна как прекрасный пример объектно-ориентированного проектирования, так как содержит многие характерные приемы и конструкции.
В основе ООП подхода, реализуемого средствами iostream, лежит предположение о том, что объекты обладают знанием того, какие действия следует предпринимать при вводе и выводе.
При пользовании библиотекой iostream ошибки, связанные с "перепутыванием" типов данных, исключены. Если вы используете в операции ввода-вывода переменную типа unsigned long, то вызывается подпрограмма, ответственная именно за этот тип.
Библиотека stdio поддерживает средства языка С, позволяющее использовать переменное число параметров. Но такая гибкость дается не даром - на этапе компиляции проверка соответствия между спецификацией формата, как в функциях printf() и scanf(), не выполняется.
В библиотеке iostream применен другой подход. Операторы ввода-вывода оформляются в виде выражений с применением переопределяемых функций-операторов для каждого из типов данных, встречающихся в выражении. Если вам необходимо использовать новый тип данных в операциях ввода-вывода, вы можете расширить библиотеку iostream своими функциями-операторами.
Библиотека iostream более медленная, чем stdio, но это небольшая плата за надежность и расширяемость, базирующиеся на возможностях объектно-ориентированных средств вывода.
Для начала рассмотрим основы применения iostream, то есть, как читать и писать данные встроенных в С++ типов. Затем обсудим, как строить собственные операции потокового ввода и вывода (операторы внесения и извлечения) для разработанных вами типов данных.
Декомпозиция и абстракция
Итак, целью при декомпозиции программы является создание модулей, которые в свою очередь представляют собой небольшие программы, взаимодействующие друг с другом по хорошо определенным и простым правилам
На этапе декомпозиции задачи на подзадачи следует придерживаться трех правил:
1.каждая подзадача должна иметь один и тот же уровень рассмотрения,
2.каждая подзадача может быть решена независимо,
3.полученные решения могут быть объединены вместе, позволяя решить исходную задачу.
Декомпозиция - весьма полезный инструмент для решения задач в различных областях. Однако при неумелом использовании она не может принести желаемого эффекта. К числу наиболее распространенных проблем относится ситуация, когда объединение решений подзадач не приводит к решению исходной. Как правило, такое случается для больших и плохо понимаемых задач.
Пример. Группа авторов создает пьесу, причем каждый из них пишет текст для одного персонажа. Очевидно, что хотя каждый из авторов и справится со своей задачей, о смысле готового произведения говорить не приходится.
Поэтому стадии декомпозиции должен предшествовать этап абстракции.
Абстракция подразумевает собой процесс изменения уровня детализации программы. Когда мы абстрагируемся от проблемы, мы предполагаем игнорирование ряда подробностей с тем, чтобы свести задачу к более простой.
После чего декомпозиция такой задачи окажется более простой по сравнению с исходной.
Пример. Группа авторов предварительно оговаривает сюжет пьесы, смысл отдельных диалогов и т.п.
Задача абстрагирования и последующей декомпозиции типична для процесса создания программ. Декомпозиция используется для разбиения программ на компоненты, которые затем могут быть объединены, позволив решить основную задачу, абстрагирование же предлагает продуманный выбор таких компонент. Последовательно выполняя то один, то другой процесс можно свести исходную задачу к подзадачам, решение которых известно.
Как уже упоминалось, процесс абстракции может быть выражен как некоторое обобщение. Оно позволяет рассматривать различные предметы, так как если бы они были эквивалентны за счет выделения существенных атрибутов от несущественных. Одним из первых шагов на пути понятия процесса абстракции мы все проделали еще в первых классах школы, когда от конкретной задачи "3 яблока + 2 груши = ? фруктов" перешли к осознанию более абстрактного выражения "3+2 = ?", а затем и вовсе "X+Y = ?".
Использование в программировании языков высокого уровня хотя и позволяет не манипулировать напрямую кодами машинных инструкций, что существенно упрощает процесс написания программ, однако зачастую конструкции, написанные на таком языке, не удовлетворяют необходимому уровню абстракции.
Сравним, например, два фрагмента кода
|
int i,a[100]; : int iaMax = 0; int aMax = a[0]; for (i=1; i<100; i++) { if (a[i]>aMax) { aMax = a[i]; iaMax = i; } } : |
int i,a[100]; : int iaMax = 99; int aMax = a[99]; for (i=98; i>=0; i--) { if (a[i]>aMax) { aMax = a[i]; iaMax = i; } } : |
Было бы гораздо удобнее обладать некоторым мощным набором примитивов для манипуляции со структурами данных. Так, если бы существовали примитивы GetMaxValue и GetMaxIndex, тогда рассматриваемая задача легко реализуется
aMax = GetMaxValue (a);
iMax = GetMaxIndex (a);
Но предусмотреть необходимость использования всех абстракций такого рода было бы достаточно сложно для разработчика языка программирования, иначе говоря, нельзя реализовать все абстракции для всех случаев жизни. Было бы гораздо более эффективным предусмотреть в языке программирования такие механизмы, которые позволяли бы программисту создавать свои собственные абстракции по мере необходимости. Наиболее распространенным механизмом такого рода является использование процедур (или функций в языке С). Разделяя в программе тело процедуры и обращение к ней, язык позволяет реализовать два важных метода абстракции: абстракцию через параметризацию и абстракцию через спецификацию.
Доступ к защищенным элементам класса
Как вы, наверное, помните, одно из основных требований для написания хороших программ с использованием объектно-ориентированного подхода состоит в том, чтобы максимально исключить возможность манипулирование элементами данными напрямую. Вместо этого должен быть представлен достаточно широкий набор методов, через которые должен осуществляться доступ к данным для их наблюдения, модификации и др.
Однако иногда использование методов для доступа к элементам данным может оказаться неудобным и неэффективным (поскольку на вызов метода требуется некоторое время). При этом речь может идти о доступе к элементам данным различных классов.
Например, рассмотрим новую функцию для нашего старого примера. Ее суть состоит в том, чтобы определить, лежит ли некоторый объект типа Point внутри области, занимаемой некоторым объектом типа Circle. Иными словами, нужно определить находится ли точка внутри окружности.
Для решения этой задачи нужны:
- координаты точки,
- координаты центра,
- радиус окружности.
Как видите все необходимые для этого данные лежат в областях private и protected.
Можно, конечно, написать новый метод для класса Circle, типа
Boolean Circle::IsInside(Point &P)
{
if ((X-P.GetX())*(X-P.GetX())+(Y-P.GetY())*(Y-P.GetY())<= R*R) return true;
else return false;
}
Но можно реализовать такую процедуру по-другому. И тому можно найти оправдание. Во-первых, вызов методов GetX() и GetY() для точки P можно здесь считать не очень элегантным, в чем-то даже громоздким. Было бы эффективнее непосредственно обращаться к X и Y. Однако если вы помните X и Y объявлены в разделе protected. Во вторых, методы определяются как процедуры для наблюдения и модификации элементов данных и вроде как, написание метода IsInside() не совсем оправдано, поскольку он не отвечает требованиям, предъявляемым к методам.
Тогда как же можно реализовать функцию, не являющуюся методом класса, но в тоже время, имеющую доступ к необщим членам класса.
Для того чтобы класс мог предоставлять функциям-неэлементам доступ к своей приватной части используется механизм объявления, так называемых, функций-друзей (friend) класса или дружественных функций. Для этого в декларации класса помещается декларация функции, перед которой стоит ключевое слово friend.
Один особенно полезный аспект механизма friend состоит в том, что функция может быть другом двух и более классов.
Посмотрим, как можно использовать механизм дружественных функций в нашем примере.
Для начала дополним декларацию классов Point и Circle:
class Point
{
//...
friend Boolean IsInside (Circle &C, Point &P);
};
class Circle: public Point
{
//...
friend Boolean IsInside (Circle &C, Point &P);
};
Заметьте, что объявление дружественной функции
friend Boolean IsInside (Circle &C, Point &P);
можно с одинаковым эффектом вставлять в любом месте в декларации класса, это может быть любой раздел (public, protected или даже private).
Сама функция будет:
Boolean IsInside(Circle &C, Point &P)
{
if ((C.X-P.X)*(C.X-P.X)+(C.Y-P.Y)*(C.Y-P.Y)<= C.R * C.R) return true;
else return false;
}
Таким образом, функция IsInside(), обычная функция (обычная в том смысле, что не является функцией элементом какого-то класса) получает доступ к приватной и защищенной областям классов Point и Circle. Обеспечить возможность такого доступа можно только в декларации класса. Так что в этом смысле инкапсуляция и защищенность данных сохраняется, поскольку полностью исключается всякая возможность такого доступа так, чтобы класс об это "не знал".
Теперь несколько слов о вариантах проявления механизма дружественных функций
Функция-элемент одного класса может быть дружественной иному классу. Например
class x
{
//...
void f();
};
class y
{
//...
friend void x::f();
};
Не исключен и такой вариант, когда все функции одного класса - дружественны другому классу. Для такого случая есть даже сокращенная запись
class y
{
//...
friend class x;
}
Дружественные функции
Доступ к защищенным элементам класса.
Переопределение операторов с помощью дружественных функций.
Файловые и строковые потоки
Одной из самых привлекательных возможностей библиотеки iostream является то, что она одинаково совершенно работает с различными источниками данных для ввода и вывода: клавиатурой и экраном, файлами и строками. Главное, что вы должны сделать, чтобы использовать строку или файл с библиотекой iostream,- это создать объект определенного типа.
Первостепенная задача при создании таких объектов - это организация буфера и связывание его с потоком.
При создании выходных файловых потоков вначале создается объект для буферизации типа filebuf, а затем этот объект связывается с новым объектом типа ostream для последующего вывода в этот новый объект.
filebuf mybuff; // создаем буферный объект
// увязывем этот буфер с файлом output для вывода
mybuff.open("output", ios::out);
ostream mycout(&mybuff); // новый потоковый объект
mycout <<12<<ends;
mybuff.close();
Аналогичные операции можно проделать при реализации извлечения из файла-буфера. Но можно поступить и по-другому, используя буферизированные файловые потоки трех видов
ifstream - для ввода,
ofstream - для вывода,
fstream - для ввода и вывода.
Например,
int i;
// сразу создается буферизованный потоковый объект, связанный // с файлом input
ifstream mycout("input");
mycin >> i;
Если в своей программе собираетесь использовать файловые потоки, то не забудьте внести в нее заголовочный файл fstream.h.
Если будите применять строковые потоки, то нужно подключить заголовочный файл strstrea.h.
Для выходных строковых потоков вы можете выделить буфер в программе или предоставить потоку возможность самому создать буфер динамически, но в таком случае придется заботиться о доступе к буферу, удалении и высвобождении выделенной под буфер памяти.
char mybuff[128];
ostrstream mycout (mybuff, sizeof(mybuff));
mycout << 123 << ends;
При этом mybuff примет значение "123".
Аналогично для ввода,
int i;
char mybuff[128]= "123";
istrstream mycin (mybuff, sizeof(mybuff));
mycin >> i;
После этого i примет значение 123.
Для входных строковых потоков можно использовать символьный массив с завершающим нулем, либо указав точный размер.
| [назад] | [оглавление] | [вперед] |
Функции библиотеки iostream
Основное отличие профессионального программиста от любителя заключается в том, что он проверяет все входные данные. В библиотеке iostream для этого используются специальные методы класса ios и двух его наследников istream и ostream. Всего в этих классах находится порядка 25 методов, позволяющих получить информацию о состоянии объектов и управлять их поведением. Вот некоторые из них.
| имя функции | действие |
| int good () | возвращает 1, если ошибок не обнаружено |
| int eof () | возвращает 1, если поток находится в состоянии "коней файла" |
| int fail () | возвращает 1, если обнаружена восстановимая ошибка ввода-вывода (обычно, ошибка преобразования данных) |
| int bad () | возвращает 1, если обнаружена невосстановимая ошибка ввода-вывода |
| int clear () | сбрасывает состояние ошибки ввода-вывода |
| int precision (int i) | устанавливает точность вывода чисел с плавающей точкой |
| int width (int i) | устанавливает ширину поля вывода |
Как теперь можно изменить нашу программу, усилив ее проверкой на ошибки при вводе.
#include <iostream.h>
int i;
char buff[80];
do{
if (cin.fail()) cin.clear(); // сброс состояния ошибки
cout << "Введите число и символьную строку:";
cin >> i;
if (cin.fail())
{
cout << "Нужно ввести число";
continue;
}
cin >> buff;
if (cin.fail())
{
cout << "Нужно ввести строку";
continue;
}
} while (cin.fail()&&!cin.bad());
if (!cin.bad())
{
cout << "Вы ввели число:" << i << "\n"
<< "Вы ввели строку:" << buff << "\n";
}
Обратите внимание на условие повторения цикла. Условие повторение цикла означает, что нужно повторить цикл, если произошла восстановимая ошибка (как правило, это ошибка преобразования), но только в том случае, если есть возможность восстановления. Единственная ошибка, которая может вызвать аварийное завершение - это переполнение 80-символьного буфера для ввода строки. Можно решить и эту проблему, указав объекту cin размер буфера, используя метод width() класса ios.
cin.width(sizeof(buff));
cin >> buff;
Инкапсуляция
Инкапсуляция - это механизм, который объединяет данные и методы, манипулирующие этими данными, и защищает и то и другое от внешнего вмешательства или неправильного использования. Когда методы и данные объединяются таким способом, создается объект.
Внутри объекта данные и методы могут обладать различной степенью открытости (или доступности). От общедоступных до таких, которые доступны только из методов самого объекта. Обычно отрытые члены класса используются для того, чтобы обеспечить контролируемый интерфейс с его закрытой частью.
Т.о., комбинирование структуры данных с функциями (действиями или методами), предназначенными для манипулирования данными, называется инкапсуляцией.
Классы и объекты
Встраиваемые функции.
Конструкторы и деструкторы.
Конструкторы с параметрами и перегрузка конструкторов.
Присваивание объектов.
Передача в функции и возвращение объектов.
Указатели и ссылки на объекты.
Классы операций
Операции абстракции данных распадаются на четыре класса.
1. Примитивные конструкторы. Эти операции создают объекты, соответствующего им типа, не используя никаких объектов в качестве аргументов. Примером такой операции является создание пустого списка.
2. Конструкторы. Эти операции используют в качестве аргументов объекты соответствующего им типа и создают другие объекты такого же типа. Например, операция сложения матриц создает новую матрицу.
3. Модификаторы. Эти операции модифицируют объекты соответствующего им типа. Например, операция push для стека.
4. Наблюдатели. Эти операции используют в качестве аргумента объекты соответствующего им типа и возвращают элемент другого типа, они используются для получения информации об объекте. Сюда относятся, например, операции типа size. Обычно примитивные конструкторы создают не все, а только некоторые объекты. Другие объекты создаются конструкторами и модификаторами. Иногда наблюдатели комбинируются с конструкторами и модификаторами (pop).
Теперь скажем несколько слов о полноте новых типов данных.
Консольный ввод и вывод в С++
Хотяв С++ по-прежнему доступны функции ввода - вывода printf() и scanf() из языка С, С++ обеспечивает иной, лучший способ выполнения этих операций. В С++ ввод/вывод выполняется с использование переопределенных операций << и>>, а не с помощью функций. Сохраняя свои первоначальные значение (левый и правый сдвиг), операции << и >> выполняют еще ввод и вывод.
Для вывода на экран применяется следующая процедура
cout << выражение;
Таким способом можно вывести любой базовый тип данных С++.
Аналогичным образом можно осуществлять и ввод (вместо scanf()).
Например,
int i;
cin >> i;
Обратите внимание, что переменной i не должен предшествовать &. В общем случае, для ввода с клавиатуры следует использовать следующую форму >>:
cin >> выражение;
Для использования операций ввода/вывода в С++, в программу необходимо включить заголовочный файл iostream.h.
Конструкторы и деструкторы
Рассмотрим наш пример с трехмерным вектором. При объявлении класса _3d мы использовали struct{}, а, следовательно, данные и методы были по умолчанию общедоступными. Это, в частности, означает, что следующий пример, вообще говоря, вполне правилен:
_3d vectorA;
double m;
vectorA.x = 17.56;
vectorA.y = 35.12;
vectorA.z = 1.0;
m = vectorA.mod();
Однако по догматам ООП такой стиль программирования должен быть признан ошибочным, так как, по идее, все элементы, описывающие состояния объекта, должны быть скрыты внутри него и доступны лишь только с помощью посылаемых объекту сообщений. Если поменять ранее данное определение класса _3d на следующее:
class _3d
{
double x, y, z;
public:
double mod () {return sqrt (x*x + y*y +z*z);}
double projection (_3d r) {return (x*r.x + y*r.y + z*r.z) / mod();}
_3d operator + (_3d b);
};
мы получим "идейно грамотное" решение. Но при компиляции предыдущего фрагмента будет диагностирована попытка обратиться к защищенному элементу класса. Это замечательно, поскольку заставит Вас дополнить интерфейс класса методами, позволяющими присвоить значения координатам вектора.
Следующая версия класса может выглядеть примерно так:
class _3d
{
double x, y, z;
public:
double mod () {return sqrt (x*x + y*y +z*z);}
double projection (_3d r) {return (x*r.x + y*r.y + z*r.z) / mod();}
void set (double newX, double newY, double newZ)
{
x = newX; y = newY; z = newZ;
}
_3d operator + (_3d b);
};
Метод set() позволяет присвоить некоторые начальные значения координатам вектора (и только этот метод!).
Еще одно замечание: хотя x, y и z теперь относятся к защищенным членам класса, явное обращение этим элементам объекта, переданного в качестве параметра (см. метод projection(...) и оператор "+"), по-прежнему допускается.
Если Вы писали программы, то знаете, что при объявлении переменной, как правило, ее инициализируют. С++ дает нам возможность создать метод, который будет автоматически вызываться для инициализации объекта данного типа при его создании. Такой метод называется конструктором. Конструктор определяет, как будет создаваться новый объект, когда это необходимо, может распределить под него память и инициализировать ее. Он может включать в себя код для распределения памяти, присваивание значений элементам, преобразование из одного типа в другой и многое полезное.
Конструкторы в языке С++ имеют имена, совпадающие с именем класса. Конструктор может быть определен пользователем, или компилятор сам сгенерирует конструктор по умолчанию. Конструктор может вызываться явно, или неявно. Компилятор сам автоматически вызывает соответствующий конструктор там, где Вы определяете новый объект класса. Конструктор не возвращает никакое значение, и при описании конструктора не используется ключевое слово void.
Функцией, обратной конструктору, является деструктор. Эта функция обычно вызывается при удалении объекта. Например, если при создании объекта для него динамически выделялась память, то при удалении объекта ее нужно освободить. Локальные объекты удаляются тогда, когда они выходят из области видимости. Глобальные объекты удаляются при завершении программы.
В языке С++ деструкторы имеют имена: "~имя_класса". Как и конструктор, деструктор не возвращает никакое значение, но в отличие от конструктора не может быть вызван явно. Конструктор и деструктор не могут быть описаны в закрытой части класса.
class _3d
{
double x, y, z;
public:
_3d();
~_3d()
{
cout << 'Работа деструктора _3d \n';
}
double mod () {return sqrt (x*x + y*y +z*z);}
double projection (_3d r) {return (x*r.x + y*r.y + z*r.z) / mod();}
void set (double newX, double newY, double newZ)
{
x = newX; y = newY; z = newZ;
}
};
_3d::_3d() // конструктор класса _3d
{
x=y=z=0;
cout << 'Работа конструктора _3d \n';
}
main()
{
_3d A; // создается объект A и происходит инициализация его элементов
// A.x = A.y = A.z = 0;
A.set (3,4,0); // Теперь A.x = 3.0, A.y = 4.0, A.z = 0.0
cout << A.mod()<<'\n';
}
Результат работы программы:
Работа конструктора _3d
5.0
Работа деструктора _3d
Конструкторы и деструкторы при наследовании
Базовый класс, производный класс или оба могут иметь конструкторы и/или деструкторы.
Если и у базового и у производного классов есть конструкторы и деструкторы, то конструкторы выполняются в порядке наследования, а деструкторы - в обратном порядке. Т.е. если А базовый класс, В - производный из А, а С - производный из В (А-В-С), то при создании объекта класса С вызов конструкторов будет иметь следующий порядок: конструктор А - конструктор В - конструктор С. Вызов деструкторов при разрушении этого объекта произойдет в обратном порядке: деструктор С - деструктор В - деструктор А.
Понять закономерность такого порядка не сложно, поскольку базовый класс "не знает" о существовании производного класса, любая инициализация выполняется в нем независимо от производного класса, и, возможно, становится основой для инициализации, выполняемой в производном классе. С другой стороны, поскольку базовый класс лежит в основе производного, вызов деструктора базового класса раньше деструктора производного класса привел бы к преждевременному разрушению производного класса.
class BaseClass
{
public:
BaseClass() {cout << ' Работа конструктора базового класса \n';}
~BaseClass() {cout << ' Работа деструктора базового класса \n';}
};
class DerivedClass: public BaseClass
{
public:
DerivedClass() {cout << ' Работа конструктора производного класса \n';}
~DerivedClass() {cout << ' Работа деструктора производного класса \n';}
};
main()
{
DerivedClass obj;
}
Эта программа выводит следующее
Работа конструктора базового класса
Работа конструктора производного класса
Работа деструктора производного класса
Работа деструктора базового класса
Мы уже говорили о том, что конструкторы могут иметь параметры. При реализации наследования допускается передача параметров для конструкторов производного и базового класса. Если параметрами обладает только конструктор производного класса, то аргументы передаются обычным способом. Однако при необходимости передать аргумент конструктору родительского класса, требуется несколько большее усилие. Прежде всего, нужно позаботится о том, чтобы передать из конструктора производного класса конструктору базового класса. Для этого используется расширенная запись конструктора производного класса.
Конструкторы с параметрами и перегрузка конструкторов
Конструкторы могут иметь параметры. Для этого просто нужно добавит необходимые параметры в объявление и определение конструктора. Затем, при создании объекта, задайте параметры в качестве аргументов.
class _3d
{
double x, y, z;
public:
_3d ();
_3d (double initX, double initY, double initZ);
...
};
_3d::_3d(double initX, double initY, double initZ)
//конструктор класса _3d с параметрами
{
x = initX;
y = initY;
z = initZ;
cout << 'Работа конструктора _3d \n';
}
main()
{
_3d A; //создается объект A и происходит инициализация его элементов
// A.x = A.y = A.z = 0;
A.set (3,4,0); //Теперь A.x = 3.0, A.y = 4.0, A.z = 0.0
_3d B (3,4,0); //создается объект B и происходит инициализация его элементов
// B.x = 3.0, B.y = 4.0, B.z = 0.0
}
Такой способ вызова конструктора является сокращенной формой записи выражения
_3d B = _3d (3,4,0);
В отличие от конструктора, деструктор не может иметь параметров. Оно и понятно, поскольку отсутствует механизм передачи параметров удаляемому объекту.
В этом примере сознательно вместе с новым объектом B оставлен объект A, чтобы продемонстрировать различные способы создания объектов. Каждому способу объявления объекта класса должна соответствовать своя версия конструкторов класса. Если это не будет обеспечено, то при компиляции программы обнаружится ошибка.
На этом примере легко понять, чем может быть вызвана необходимость перегрузки конструкторов. Именно перегрузки, поскольку речь здесь идет о функциях, имеющих одинаковые имена, но различные списки параметров. Главный смысл перегрузки конструкторов состоит в том, чтобы предоставить программисту наиболее подходящий метод инициализации объекта.
В нашем примере представлен наиболее распространенный вариант перегрузки конструкторов, т.е. конструктор без параметров и конструктор с параметрами. Как правило, в программе бывают необходимы оба эти вида, поскольку конструктор с параметрами более удобен при работе с одиночными объектами, но не может использоваться при инициализации объектов-элементов динамического массива (для статического массива может).
Хотя конструктор можно перегружать столько раз, сколько захотите, лучше не стоит этим злоупотреблять. Конструктор стоит перегружать лишь для наиболее часто встречающихся ситуаций.
КОНТРОЛЬНЫЕ ВОПРОСЫ
Какие существуют механизмы для создания новых типов? В чем смысл декомпозиции при составлении программ? В чем различие между видами и методами (способами) абстракции? Классы операций абстракции данных. Полнота класса операций. Парадигма ООП. Специфика интерфейса ОО программ. Преимущества ООП. Понятие класса. Отношение "объект - класс". Понятие полиморфизма. Проявления полиморфизма. Механизм наследования. Модификатора доступа и наследования. Как изменяются атрибуты элементов класса при наследовании? Смысл инкапсуляции. В чем разница между struct, class и union? Что такое конструктор, деструктор и когда они вызываются? Что такое встраиваемая функция? В чем ее преимущества и недостатки? Какие два способа существуют для создания встраиваемой функции? Как можно передать в функцию в качестве аргумента адрес объекта? Что такое дружественная функция? Когда следует переопределять операторы с помощью дружественных функций, а когда с помощью функций элементов класса? Что происходит при присваивании одного объекта другому (без переопределенной операции =) и какие побочные эффекты могут возникнуть? При передаче объекта в функцию в качестве аргумента создается копия этого объекта. Изменение копии в теле функции не отражается на оригинале. Возможно ли нарушение этого правила? Какая функция может иметь доступ к защищенным членам одного класса? ... двух классов? Что такое указатель this. Приведите пример использования этого указателя. Для чего необходимы операторы new и delete. В чем их отличие от функций malloc() и free()? Что такое ссылка? Какое имеется преимущество при использовании ссылки в качестве параметра функции, а в чем недостаток? В чем разница между ссылкой и указателем? Назовите причины, по которым может понадобиться перегрузка конструкторов и деструкторов (в одном классе). Какова основная форма конструктора копирования и когда он вызывается? Что такое аргумент по умолчанию? Как аргумент по умолчанию связан с перегрузкой функций? Почему может потребоваться перегрузка оператора присваивания? Как можно ли изменить приоритет перегруженного оператора? Что такое виртуальная функция? Какие функции не могут быть виртуальными? Что такое абстрактный класс и чем может быть вызвана необходимость построений абстрактного класса? Чем виртуальные функции отличаются от перегружаемых? Раннего и позднее связывание. Совместимость типов. Какую роль в достижении совместимости объектов могут играть абстрактные классы? Почему шаблоны называют параметризованными типами? Когда следует в программе применять шаблоны, а когда нет? Чем шаблоны лучше макроподстановок? Для каких типов данных может применяться конкретный шаблон, а для каких нет? В чем разница между классом и шаблоном класса? Что может выступать в качестве параметра для шаблона класса? В чем основное преимущество использования библиотеки потокового ввода-вывода? Как работает операция внесения (на примере)? Что такое манипулятор ввода - вывода? Организация файлового и строкового потока.
ЛИТЕРАТУРА
Шилдт Герберт. Самоучитель С++ (2-ред)./Пер. с англ.-СПб.: BHV-Санкт-Петербург, 1997.-512с. (+дискета с примерами) Бруно Бабэ. Просто и ясно о Borland C++: Версии 4.0 и 4.5/ Пер. с англ. -М.:БИНОМ, 1994. - 400с. Страуструп Б. Язык программирования С++ (2-ред)./Пер. с англ.-М.: Радио и связь, 1995. - 352с. Клочков Д.П., Павлов Д.А. Введение в объектно-ориентированное программирование. / Учебно-методическое пособие. - Изд. Нижегор. ун-та, 1995. - 70с. Элиас М., Страуструп Б. Справочное руководство по языку С++ с комментариями. /Пер. с англ. -М.:Мир, 1992.- с.
Манипуляторы ввода -вывода
Кроме представленных ранее методов, существует и другой способ управления процессом ввода-вывода, основанный на использовании манипуляторов ввода-вывода. Манипуляторы позволяют менять режимы операций ввода-вывода непосредственно в выражениях внесения или извлечения. Для того чтобы использовать их в своей программе, в исходные тексты нужно включить заголовочный файл iomanip.h.
В прошлый раз мы накладывали ограничение на размер буфера cin, применяя метод width():
cin.width(sizeof(buff));
cin >> buff;
Теперь, используя манипулятор setw(), можно определить размер буфера так
cin >> setw (sizeof (buff)) >> buff;
Существует два вида манипуляторов ввода-вывода: параметризованные и непараметризованные. Вот список стандартных манипуляторов библиотеки iostream()
| манипулятор | i/o | описание |
| dec | o | устанавливает базу для преобразования чисел к 10-, |
| oct | o | 8- |
| hex | o | и 16-ичной форме |
| ws | i | пропуск начальных пробелов |
| ends | o | выводит нулевой символ |
| endl | o | Выводит признак конца строки |
| setfill (int ch) | o | Устанавливает символ-заполнитель |
| setprecision(int n) | o | Устанавливает точность вывода чисел с плав точкой (знаков после запятой) |
| setbase (int b) | o | устанавливает ширину поля для последующей операции |
| setbase (int b) | o | устанавливает базу для преобразования числовых значений |
| setiosflags (int f) | i/o | устанавливает отдельные флаги потока |
| resetiosflags (int f) | i/o | сбрасывает отдельные флаги потока |
Вот некоторые из флагов потока
| флаг | описание |
| left | выравнивание по левому краю |
| right | выравнивание по правому краю |
| dec, oct, hex | устанавливают базу для ввода-вывода |
| showbase | выводить показатель базы |
| showpoint | выводить десятичную точку для чисел с плав точкой |
| uppercase | 16-ричные большие буквы |
| showpos | показать "+" для положительных целых чисел |
| scientific | установить экспон форму для чисел с плав точкой |
| fixed | установить формат чисел с фиксированной плав точкой |
Кроме того, вы можете создать свой собственные манипуляторы. Этому могут быть, по крайней мере, две причины. Во-первых, это может быть манипулятор, заключающий в себе некоторую часто встречающуюся в программе последовательность манипуляторов. Во-вторых, для управления нестандартными устройствами ввода-вывода.
Создание непараметризованных манипуляторов не очень сложное занятие. Все, что для этого нужно, это определить функцию, имеющую прототип, похожий на следующий:
ios& manipul (ios&);
Если вы пишите манипулятор только для вывода, ios замените на ostream, если для ввода - на istream.
В теле функции можно, что-то сделать с потоком, переданным в качестве параметров, а затем передать его в вызывающую программу на переданный функции аргумент типа поток.
Вот пример манипулятора для вывода с выравниванием по правому краю:
ostream & right(ostream &)
{
s << resetiosflags(ios::left) << setiosflags(ios::right);
return s;
}
Функция манипулятор изменяет биты флагов потока, переданного ей в качестве аргумента. После того, как right установит биты флагов потока, последний будет выводиться в таком режиме до тех пор, пока флаги потока не будут изменены.
Таким образом, выражение
cout << setw(20) << right<< 1234 << endl;
означает следующее. Манипулятор setw(20) установит поле вывода шириной 20 символов, манипулятор right установит выравнивание по правой границе поля вывода, выведется число, а манипулятор endl вызовет переход к следующей строке.
Параметризованные манипуляторы более сложны в написании, так как в этом случае необходимо создать класс, содержащий указатель на функцию - манипулятор и указатель на аргументы функции манипулятора. Макроопределения, которые облегчат процесс разработки параметризованных манипуляторов, содержатся в заголовочном файле iomanip.h.
Методология программирования
Декомпозиция и абстракция. Абстракция через параметризацию. Абстракция через спецификацию. Процедурная абстракция. Абстракция данных.
Классы операций.
Полнота.
Сейчас мы немного поговорим об общей методологии составления программ. Конечно, не стоило бы заводить об этом разговор, если бы мы ограничивались написанием только небольших программ, т.е. программ, содержащих до нескольких сотен строк. Такие программочки легко охватить взором как единую и неделимую единицу. Однако по мере увеличения размера программы такая монолитность становиться не удобной. Поэтому программа должна быть разбита на ряд независимых программ, называемых модули. А сам процесс разбиения назовем декомпозицией. Необходимость декомпозиции становится все более и более очевидной, когда возрастает размер программы, а в процесс составления программ вовлекается много людей.
По этой причине программа может быть разбита на части, причем каждая их них может создаваться отдельными участниками относительно независимо от остальных. Кроме того, следует учитывать и такой немаловажный факт, как вопросы модификации и сопровождения программ, по возможности не сопровождая этот процесс полной переделкой. В таких случаях предпочтительнее вносить изменения в существующую структуру и, следовательно, важно, чтобы структура допускала возможность такой модификации. В частности, необходимо, чтобы части были независимы друг от друга, что позволяло бы вносить изменения в один модуль, не изменяя другие. Нужно учитывать и тот факт, что вопросами сопровождения программного продукта, как правило, занимается вовсе не его разработчик, поэтому еще одна цель, которую преследует структурируемость программ, - это простота понимания программы.
Модификаторы наследования
Мы, наконец, готовы поговорить о наследовании. Это одно из наиболее интересных качеств языка С++. Наследование в С++ - это механизм, посредством которого один класс может наследовать свойства другого. Наследование позволяет строить иерархию классов, переходя от более общих к более специальным.
Когда один класс наследуется другим, класс, который наследуется, называется базовым классом. Наследующий класс называют производным классом.
Новый класс строится на базе уже существующего с помощью конструкции следующего вида:
class Parent {....};
class Child : [модификатор наследования] Parent {....};
При определении класса потомка за его именем следует разделитель-двоеточие (:), затем - необязательный модификатор наследования и имя родительского класса. Модификатор наследования определяет видимость наследуемых переменных и методов для пользователей и возможных потомков самого класса-потомка. Другими словами, он определяет, какие права доступа к переменным и методам класса-родителя будут "делегированы" классу-потомку. При реализации наследования, область "видимости" принадлежащих классу данных и методов можно определять выбором ключевого слова private (собственный), public (общедоступный) или protected (защищенный), которые могут произвольно чередоваться внутри описания класса. С двумя первыми модификаторами доступа мы уже знакомы, - private описывает закрытые члены класса, доступ к которым имеют только методы-члены этого класса, public предназначен для описания общедоступных элементов, доступ к которым возможен из любого места в программе. Особый интерес представляют элементы, обладающие модификатором доступа protected. Модификатор protected используется тогда, когда необходимо, чтобы некоторые члены базового класса оставались закрытыми, но были бы доступны для производного класса. Protected эквивалентен private с единственным исключением: защищенные члены базового класса доступны для членов всех производных классов этого базового класса.
То, как изменяется доступ к элементам базового класса из методов производного класса, в зависимости от значения модификаторов наследования, приведено в таблице.
| Модификатор наследования |
| Модификатор доступа | public | protected | private | |
| public | public | protected | private | |
| protected | protected | protected | private | |
| private | нет доступа | нет доступа | нет доступа |
Наследование
Наследование - это процесс, посредством которого, один объект может приобретать свойства другого. Точнее, объект может наследовать свойства другого объекта и добавлять к ним черты, характерные только для него.
Обычно, если объекты соответствуют конкретным сущностям реального мира, то классы являются абстракциями, выступающими в роли понятий. Между классами, как между понятиями существует иерархическое отношение конкретизации, связывающее класс с надклассом. Это отношение реализуется в системах ООП механизмом наследования.
Исследователи в различных областях естествознания тратят много времени на классификацию объектов в соответствии с определенными особенностями. В этом часто помогает организация классификации в форме фамильного дерева с одной общей категорией в корне и подкатегориями, разветвляющимися на подкатегории и т.д.
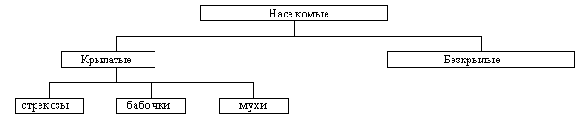
Например, энтомологи классифицируют насекомых как показано на рисунке (схема очень упрощена). Внутри типа насекомых есть два деления: крылатые и бескрылые. Среди крылатых насекомых существует большее количество категорий: мотыльки, бабочки, мухи и т. д.
Частичная таксономическая схема насекомых
Такой процесс классификации называется таксономией. Это хорошая начальная метафора для понимания механизма наследования в ООП.
Пытаясь провести классификацию некоторых новых животных или объектов, мы задаем следующие вопросы: В чем сходство этого объекта с другими объектами общего класса? В чем он различия? Каждый класс имеет набор поведений и характеристик, которые его определяют. Мы начинаем с верхушки фамильного дерева образца и будем спускаться по ветвям, задавая эти вопросы на протяжении всего пути. Более высокие уровни являются более общими, а вопросы более простыми: есть крылья или нет крыльев? Каждый уровень является более специфическим, чем предыдущий уровень и менее общим.
Когда характеристика определена, все категории ниже этого определения включают эту характеристику. Поэтому, когда Вы идентифицируете насекомое как члена отряда двукрылых (мухи), то Вам не нужно указывать, что муха имеет пару крыльев. Вид "муха" наследует эту характеристику из своего отряда.
Другой пример: "дом" - это часть общего класса "строение", "строение" - часть более общего класса "конструкция", которая является частью еще более общего класса объектов, который можно назвать "созданием рук Человека". Каждый раз порожденный класс наследует все, связанное с родителем, и добавляет к ним свои собственные определяющие характеристики. Не описав такой иерархии, для каждого объекта пришлось бы задавать все характеристики, которые бы его исчерпывающе определяли.
ООП - это процесс построения иерархии классов. Одним из наиболее важных свойств, которое С++ добавляет к С, является механизм, по которому типы классов могут наследовать характеристики из более простых, общих типов. Этот механизм называется наследованием. Наследование обеспечивает общность функций, в то же время допуская столько особенностей, сколько необходимо. Если класс D наследует из класса В, то мы говорим, что D - это порожденный класс, а В - основной класс.
Без сомнения это тривиальная задача, но установить идеальную иерархию классов для определенного применения очень трудно. Таксономия насекомых развивалась сотни лет и до сих пор подвергается изменениям и саркастическим дебатам. Прежде чем Вы напишите строку С++ кода, Вы должны хорошо подумать о том, какие классы необходимы и на каком уровне. По мере того как увеличивается применение, может оказаться, что необходимы новые классы, которые фундаментально изменяют всю иерархию классов. Растущее число изготовителей поставляют C++ с совместимыми библиотеками классов. Иногда Вы сталкиваетесь с классом, который комбинирует свойства более чем одного предварительно определенного класса. Такой механизм называемый многократным наследованием, посредством которого порожденный класс может наследовать от двух или более основных классов.
Теперь настало время привести еще один совет (в дополнение к двум уже приведенным ранее) из книги Страуструпа:
"... если у двух классов есть некая общая часть, пусть она будет базовым классом. В вашей программе многие классы будут иметь нечто общее; создайте (почти) универсальный базовый класс - к его разработке отнеситесь тщательнее всего".
Т.о., наследование выполняет в ООП несколько важных функций:
- моделирует концептуальную структуру предметной области;
- экономит описания, позволяя использовать их многократно для задания разных классов;
- обеспечивает пошаговое программирование больших систем путем многократной конкретизации классов.
Наследование в языке С++
Модификаторы наследования.
Конструкторы и деструкторы при наследовании.
Пример построения классов и наследования. Совместимость типов.
Наследование в шаблонах классов
И, наконец, последнее. Шаблоны классов, как и классы, поддерживают механизм наследования. Все основные идеи наследования при этом остаются неизменными, что позволяет построить иерархическую структуру шаблонов, аналогичную иерархии классов.
Рассмотрим совершенно тривиальный пример, на котором продемонстрируем, каким образом можно создать шаблон класса, производный из нашего шаблона класса Pair. Пусть это будет класс Trio, в котором к паре элементов a и b из Pair, добавим еще один c.
template <class T>
class Trio: public Pair <T>
{
T c;
public:
Trio (T t1, T t2, T t3);
...
};
template <class T>
Trio<T>::Trio (T t1, T t2, T t3): Pair <T> (t1, t2), c(t3)
// Заметьте, что вызов родительского конструктора
// также сопровождается передачей типа Т в качестве параметра.
{}
| [назад] | [оглавление] | [вперед] |
Объектно - ориентированная технология разработки программ
В объектно-ориентированном программировании базовыми единицами программ и данных являются объекты. (Можно сказать, что в чисто объектно-ориентированной системе ничего, кроме объектов нет).
Объект- это осязаемая сущность, которая четко проявляет свое поведение.
Объект состоит из следующих трех частей:
- имя объекта;
- состояние (переменные состояния);
- методы (операции).
Интерфейс объекта с его окружением определен полностью его методами, так как к его состоянию нет другого доступа извне, как через методы.
Объект сохраняет свое состояние от обращения к обращению. Изменение состояний производится только через вызов методов этого объекта. Этим существенно ограничивается возможность введение объекта в недопустимое состояние и/или несанкционированное разрушение объекта. Возможность управлять состояниями объекта через вызов методов в конечном итоге будет определять поведение объекта.
Реализация методов (то есть, операций, выполняемых объектом), может быть задана различными способами. Однако это "внутренне дело" объекта.
Объект может посылать сообщения другим объектам и принимать сообщения от них.
Сообщение
является совокупностью данных определенного типа, передаваемых объектом отправителем объекту получателю, имя которого указывается в сообщении. Получатель реагирует или никак не реагирует (защита) на сообщение выполнением некоторой операции (метода), имя которого также может быть указано в сообщении.
На рисунке показана разница в интерфейсах функции, процедуры и объекта.

По своему смыслу объект является представителем некоторой реальной сущности - реального объекта, процесса, ситуации, которая:
- поддается хранению и обработке;
- способна воздействовать на другие объекты и вычислительную среду, посылая сообщения и реагировать на принимаемые сообщения.
Совокупность объектов в системе ООП образует среду, в которой выполняются вычисления путем обмена сообщениями между объектами. Состояние вычислительной среды в ООП оказывается разделенным на состояния объектов, это в принципе отличает объектно-ориентированные вычисления от вычислений, заданных на процедурно-ориентированных языках. Процедуры выполняются на общей памяти, в то время как объекты выполняют свои операции с учетом данных одного сообщения и своего собственного состояния.
Объекты с одинаковыми свойствами, то есть с одинаковыми наборами переменных состояния и методов, образуют класс.
Каждый класс задается своим описанием на языке ООП, которое включает информацию, необходимую для создания объектов данного класса и для их существования. (Это информация о переменных состояния и операциях объекта).
А теперь, несколько советов из книги Страуструпа:
"... Когда вы программируете, вы создаете конкретное представление идей, связанных с решением некоторой задачи. Постарайтесь, чтобы структура программы максимально отражала эти идеи:
если об "этом" можно мыслить как об отдельном понятии, пусть это будет классом;
если об "этом" можно мыслить как об отдельной сущности, то пусть это будет объектом некоторого класса..."
Иначе говоря, объектно-ориентированный подход к программированию некоторой задачи, прежде всего, состоит в том, чтобы создать некоторый инструментарий, присущий решаемой задаче, а затем уже программировать в терминах этой задачи.
Все языки ООП, включая С++, основаны на трех основополагающих концепциях, называемых инкапсуляцией, полиморфизмом и наследованием. Рассмотрим эти концепции.
Объектно-ориентированное программирование на С++
Предисловие
Содержание курса
Вопросы для самостоятельного изучения
Перечень лабораторных занятий
Литература
Контрольные вопросы
Объектно-ориентированные расширения С++
Консольный ввод и вывод в С++
Введение в классы
Перегружаемые функции и операторы (overload)
Рассмотрев свойства С++, которыми можно пользоваться, не отказываясь от традиционного подхода к программированию, обратимся к объектно-ориентированным методам программирования. Прежде всего, вспомним три основные свойства, при наличии которых можно говорить, что некоторый язык предназначен для объектно-ориентированного программирования: ИНКАПСУЛЯЦИЯ, ПОЛИМОРФИЗМ и НАСЛЕДОВАНИЕ.
С++ соответствует определению языка объектно-ориентированного программирования по всем трем классическим критериям. Правда, если Вы знакомы с языком С по описаниям Кернигана и Ритчи, Вас очень удивит новая терминология и форматы записи. В С++ привычные операторы и обозначения используются совсем иначе. По сравнению с "классическим" С Страуструп ввел всего несколько дополнительных ключевых слов и операторов, но "выжал" из них максимально много. При поверхностном взгляде программа на С++ может выглядеть очень похожей на программу на С, но операторы и выражения в ней сочетаются совсем не так.
Рассмотрим простую пробную программу, которая требует, чтобы пользователь ввел целое число и символьную строку, а затем выводит только что принятую информацию.
| Вариант на стандартном С | Вариант на С++ |
| #include "stdio.h" int i; char temp[80], buff[80]; |
printf ("Введите число:");
gets(temp); i = atoi(temp);
printf ("Введите символьную строку:");
gets (buff);
printf ("Вы ввели число: %d\n", i);
printf ("Вы ввели строку: %s\n", buff);
int i;
char buff[80];
cout << "Введите число:";
cin >> i;
cout << "Введите символьную строку:";
cin >> buff;
cout << "Вы ввели число:" << i << "\n";
cout << "Вы ввели строку:" << buff << "\n";
Эта коротенькая программа представляет собой превосходную иллюстрацию объектно-ориентированной природы С++. Здесь cin - это объект, воспринимающий ввод пользователя, cout - объект, обеспечивающий форматный вывод. Когда Вы обмениваетесь сообщениями с объектами cin и cout, форма и тип передаваемых данных определяют действия, которые требуется выполнить (полиморфизм), содержание выполняемых операций в вызывающей программе никак не отражается (инкапсуляция), и оба используемых объекта представляют собой конкретные реализации одного и того же порождающего класса iostream (наследование).
Основные конструкторы типов.
Как мы уже видели, хотя в языках программирования немало сугубо машинных деталей, в основе системы типов лежит математическая традиция.
Типы строятся, исходя из конечного набора базисных типов (называемых также простыми, примитивными, элементарными), с помощью операций - конструкторов типов.
Большинство конструкторов типов имеют прямые аналоги в математике. Итак, базисные типы - это множества целых чисел, конечных приближений вещественных чисел, литерных значений и, возможно, булевских величин.
Одним из самых простых и понятных конструкторов можно назвать объявление перечисляемого типа. Этот скалярный тип описывается простым перечислением его компонент. Хотя с теоретической точки зрения скалярные типы данных могут полностью удовлетворить потребности программиста, все же желательно иметь практическую возможность определять свои неструктурные типы, и их помощью можно более четко описать предполагаемую потенциальную область значений переменной и обеспечить возможность эффективного представления переменной. Объявление переменной перечисляемого типа определяет список именованных констант, называемый списком перечисления. Каждому элементу списка перечисления ставится в соответствие целое число. Поэтому переменной перечисляемого типа выделяется столько же памяти, сколько и для переменной типа int. Над объектами перечисляемого типа определены те же операции, что и над объектами целого типа.
enum {компонента1,...,компонентаn};
enum TColor {WHITE, YELLOW, RED, GREEN, BLUE, BLACK};
:
Tcolor color1 = WHITE, color2;
color2 = color1;
Теперь поговорим немного о другом классе типов. Это так называемые структурные типы данных. Структурные типы предоставляют возможность давать коллективное имя некоторому множеству элементов. Существует несколько способов структурирования, каждый из которых отличается способом доступа к индивидуальным компонентам. Для определения типа структурной переменной необходимо задать:
1. способ структурирования,
2. типы компонент.
Важнейшие конструкторы таких типов - это массивы и записи (структуры).
Массив позволяет хранить как единое целое последовательность переменных одного типа. Переменная, имеющая структуру массива, является совокупностью компонент-переменных одного и того же типа. У массива, однако, есть характерные особенности:
1. Каждая отдельная компонента массива может быть явно обозначена и к ней имеется прямой доступ.
2. Число компонент массива определяется при его описании и в дальнейшем не меняется.
Для обозначения компонент используется имя переменной-массива и индекс, который однозначно указывает на желаемый элемент. Тот факт, что индекс может быть вычисляемым объектом, выделяет массив среди других структур данных.
Элементы массива могут быть не только скалярами, но также и структурными компонентами. Если они сами являются массивами, то первоначальный массив называется многомерным.
С абстрактной точки зрения массив можно определить как отображение области одного типа (множество индексов) на множество значений некоторого другого типа (тип элементов). Отображение по-другому называется "функцией". Так что, массивы - это функции с конечной областью определения, то есть функции, определяемые конечной таблицей значений.
Типовой конструктор массивов в языке Си обозначается как [ ].
Тип идентификатор [размер];
В отличие от массива структура позволяет объединить в одном программном объекте совокупность значений, которые могут иметь различные типы. Список объявлений элементов представляет собой последовательность из одного и более переменных. Каждая переменная, объявленная в этом списке, называется элементом структуры. Элементы структуры могут иметь базовый тип, либо быть указателем, структурой. Элемент структуры не может быть того же типа, в которой он содержится, однако им может указатель на тип структуры, в которую он входит.
Типовое выражение, соответствующее конструктору записи
struct
{
тип1 идентификатор1;
:
типn идентификаторn;
};
Структура как конструкция аналогична декартову произведению множеств. Простым примером такого произведения является дата. Для спецификации даты достаточно трех значений: год, месяц, число месяца. Так что вполне логично для описания переменной типа TDate использовать следующую конструкцию:
enum TMonth {Jan, Feb, Mar, ..., Dec};
struct Tdate
{
int Year;
TMonth Month;
int Day;
};
:
TDate BirthDay[10];
BirthDay[3].Year = 1256;
BirthDay[3].Month = Jan;
BirthDay[3].Day = 22;
Пришедшее в язык Си из Алгола 68 понятие объединения union представляет собой размеченное объединение, где элемент множества слагаемого входит во множество с пометкой, указывающей это слагаемое. Объединение позволяет в различные моменты времени хранить в одном объекте значения различного типа. В процессе объявления объединения с ним ассоциируется набор типов значений, которые могут храниться в данном объединении. В каждый момент времени объединение может хранить значение только одного типа из набора.
Память, которая выделяется переменной типа объединение, определяется размером наиболее длинного из элементов объединения. Все элементы размещаются в одной и той же области памяти и с одного и того же адреса. Значение текущего элемента теряется, когда другому элементу объединения присваивается значение. Синтаксически объединение union записывается аналогично struct.
union
{
тип1 идентификатор1;
:
типn идентификаторn;
};
В некоторых языках имеются такие конструкторы типов, как отрезок, множество set (Паскаль), граф.
Особый интерес представляет такой конструктор типов, как указатель pointer. Указатели являются средством построения и обработки структур данных, являющихся, по существу, ориентированными графами с узлами, которые сами могут иметь сложную структуру. Указатель - это переменная, предназначенная для хранения адреса некоторого объекта. Объявление указателя специфицирует имя переменной и тип объекта, на который может указывать эта переменная. Указатель может указывать на значение базового, перечисляемого типа, структуры, объединения, массивы, функции и указатели. В языке Си указатель состоит из адреса, указывающего на объект определенного типа, то есть это типизированный указатель. Приведение указателей к определенному типу позволяет ввести аксиоматику арифметики указателей. Однако, кроме типизированных указателей, существует указатель на пустой тип (void). Указатель на void может указывать на значение любого типа. Однако для выполнения операций над указуемым объектом, необходимо привести тип указателя к типу этого объекта.
Несколько особняком стоят функции. В математике функциям уделяется большое внимание, они являются базовыми объектами. Как мы только что отметили, табличные функции виде массивов входят в систему типов. А как обстоит дело с другими функциями, теми, что представляются в виде подпрограмм (процедур), возвращающих значения?
Тут надо задать вопрос - А что такое данные? Согласно распространенной точке зрения, высказанной Никлаусом Виртом в книге "Алгоритмы + структуры данных = программа", данные - это пассивная, обрабатываемая часть программы. Но функции относятся к активной части программы, и значит, это не данные.
С другой стороны, все, что может быть аргументом ("фактическим параметром") функции, следует считать данными. Но функция, возвращающая значение, может быть использована в качестве аргумента. Какой-то порочный круг.
Выход здесь такой: функции - это данные, но данные особого рода в виду их двойной роли (активной и пассивной) в вычислениях. В языке Си, как и в Алголе 68 функции включаются в систему типов, и тип функции определяется типом возвращаемого значения.
В заключение я хочу привести Вам цитату из книги Хоара [1] по поводу структурной организации типов.
Тип определяет класс значений, которые могут принимать переменная или выражение
Каждое значение принадлежит одному и только одному типу.
Тип значения константы, переменной или выражения можно вывести либо из контекста, либо из вида самого операнда, не обращаясь к значениям, вычисляемым во время работы программы.
Каждой операции соответствует некоторый фиксированный тип ее операндов и некоторый фиксированный тип результата
Для каждого типа свойства значений и элементарных операций над значениями задаются с помощью аксиом.
При работе с языками высокого уровня знание типа позволяет обнаруживать в программе бессмысленные конструкции и решать вопрос о методе представления данных и преобразования их в вычислительной машине.
Интересующие нас типы - это типы, хорошо известные математикам: прямые произведения, размеченные объединения, множества, функции, последовательности:
Обсуждая то или иное понятие, человек стремится различить в нем три стороны: идею, формулировку и мотивировку. Идея - это содержательная, интуитивная сторона, суть дела. Формулировка - это математически точное, однозначное выражение идеи. Мотивировка - это подоплека понятия: что за ним стоит, какова его цель, в каком контексте и на каком "фоне" оно возникает.
Рассматривая с этих точек зрения определение Хоара, можно отметить, что идеи, в основном, понятны; формулировки требуют уточнения; желательна более полная мотивировка.
Пытаясь понять, что стоит за идеями и решениями, мы можем увидеть направления дальнейшего движения и факторы, которые оказывают на него влияние.
| [назад] | [оглавление] | [вперед] |
Отождествление типов аргументов
Так как компилятор генерирует экземпляры шаблонов функций согласно типам, заданным при их вызовах, то критическим моментом является передача корректных типов, особенно если шаблон функции имеет два или более параметров. Хорошим примером является классическая функция max():
template <class T>
T max (T a, T b)
{
return a > b ? a : b;
}
Функция max() будет работать правильно, если оба ее аргумента имеют один и тот же тип:
int i = max (1, 2);
double d = max (1.2, 3.4);
Однако, если аргументы различных типов, то вызов max() приведет к ошибке, так как компилятор не сможет понять, что ему делать.
Один из возможных способов для разрешения неоднозначности состоит в использовании приведения типов, чтобы прояснить наши намерения:
int i = max ((int)'a', 100);
Вторая возможность - это явно объявить версию экземпляра шаблона функции перед ее вызовом:
int max (int, int);
int j = max ('a', 100);
Третий способ решить проблему состоит в создании шаблона функций, который имеет параметры различных типов.
template <class T1, class T2>
T1 max (T1 a, T2 b)
{
return a > (T1)b ? a : (T1)b;
}
Использование этой новой версии max() не приведет к неоднозначности в случае использования двух различных типов. Например, если написать
max ('a', 100);
то компилятор будет использовать два заданных (посредством аргументов типа) и построит версию функции max() с заголовком
char max (char, int);
Далее компилятор перед выполнением сравнение приведет тип второго аргумента к типу первого аргумента. Такой способ допустим, однако использование двух типовых параметров в шаблоне функции, которая должна была бы работать только с одним типом, часто лишь затрудняет жизнь. Довольно тяжело помнить, что
max ('a', 100)
дает значение типа char, в то время как
max (100, 'a')
передает в вызывающую программу int.
ПЕРЕЧЕНЬ ЛАБОРАТОРНЫХ ЗАНЯТИЙ
(* отмечены задачи для любителей трудностей)
Создание класса и объектов типа "полином" с динамическим выделением памяти под элементы, для которого определены основные операции: сложение, вычитание, присваивание, *умножение, *деление. Реализация различных типов конструкторов для одного типа, включая конструктор копирования. Использование переопределенных операторов потокового ввода-вывода для этого нового типа.
Иллюстрация на простом примере использования объектов нового типа. Создание нескольких (не менее двух) типов для графических объектов, используя механизм наследования от классов Point или Circle. (например: квадрат, прямоугольник, возможно закрашенный, круг, сектор, *3D- объекты и т.п.)
Иллюстрация на простом примере использования объектов нового типа. Создание двухуровневой иерархии классов, где в качестве родительского класса выступает абстрактный класс, на примере абстрактного типа "график функции". При этом вид функции определяется в производном классе. Реализация операций сложения функций и умножения на константу, используя дружественные функции.
Иллюстрация на простом примере использования объектов нового типа. Использование шаблонов классов и механизма наследования для создания нового шаблона "очередь" с контролем количества элементов в очереди. В качестве базового используется шаблон класса "queue" из библиотеки classlib.
Иллюстрация на простом примере использования объектов нового типа.
Передача в функции и возвращение объекта
Объекты можно передавать в функции в качестве аргументов точно так же, как передаются данные других типов. Всем этим мы уже пользовались, когда реализовывали методы класса_3d, в котором в качестве параметров методов projection(...), operator +(...) и operator = (...) передавали объект типа _3d.
Следует помнить, что С++ методом передачи параметров, по умолчанию является передача объектов по значению. Это означает, что внутри функции создается копия объекта - аргумента, и эта копия, а не сам объект, используется функцией. Следовательно, изменения копии объекта внутри функции не влияют на сам объект.
При передаче объекта в функцию появляется новый объект. Когда работа функции, которой был передан объект, завершается, то удаляется копия аргумента. И вот на что здесь следует обратить внимание. Как формируется копия объекта и вызывается ли деструктор объекта, когда удаляется его копия? То, что вызывается деструктор копии, наверное, понятно, поскольку объект (копия объекта, передаваемого в качестве параметра) выходит из области видимости. Но давайте вспомним, что объект внутри функции - это побитная копия передаваемого объекта, а это значит, что если объект содержит в себе, например, некоторый указатель на динамически выделенную область памяти, то при копировании создается объект, указывающий на ту же область памяти. И как только вызывается деструктор копии, где, как правило, принято высвобождать память, то высвобождается область памяти, на которую указывал объект-"оригинал", что приводит к разрушению исходного объекта.
class ClassName
{
public:
ClassName ()
{
cout << 'Работа конструктора \n';
}
~ClassName ()
{
cout << 'Работа деструктора \n';
}
};
void f (ClassName o)
{
cout << 'Работа функции f \n';
}
main()
{
ClassName c1;
f (c1);
}
Эта программа выполнит следующее
Работа конструктора
Работа функции f
Работа деструктора
Работа деструктора
Конструктор вызывается только один раз. Это происходит при создании с1. Однако деструктор срабатывает дважды: один раз для копии o, второй раз для самого объекта c1. Тот факт, что деструктор вызывается дважды, может стать потенциальным источником проблем, например, для объектов, деструктор которых высвобождает динамически выделенную область памяти.
Похожая проблема возникает и при использовании объекта в качестве возвращаемого значения.
Для того чтобы функция могла возвращать объект, нужно: во-первых, объявить функцию так, чтобы ее возвращаемое значение имело тип класса, во-вторых, возвращать объект с помощью обычного оператора return. Однако если возвращаемый объект содержит деструктор, то в этом случае возникают похожие проблемы, связанные с "неожиданным" разрушением объекта.
class ClassName {
public:
ClassName ()
{
cout << 'Работа конструктора \n';
}
~ClassName ()
{
cout << 'Работа деструктора \n';
}
};
ClassName f()
{
ClassName obj;
cout << 'Работа функции f \n';
return obj;
}
main()
{
ClassName c1;
c1 = f();
}
Эта программа выполнит следующее
Работа конструктора
Работа конструктора
Работа функции f
Работа деструктора
Работа деструктора
Работа деструктора
Конструктор вызывается два раза: для с1 и obj. Однако деструкторов здесь три. Как же так? Понятно, что один деструктор разрушает с1, еще один - obj. "Лишний" вызов деструктора (второй по счету) вызывается для так называемого временного объекта, который является копией возвращаемого объекта. Формируется эта копия, когда функция возвращает объект. После того, как функция возвратила свое значение, выполняется деструктор временного объекта. Понятно, что если деструктор, например, высвобождает динамически выделенную память, то разрушение временного объекта приведет к разрушению возвращаемого объекта.
Одним из способов обойти такого рода проблемы является создание особого типа конструкторов, - конструкторов копирования. Конструктор копирования или конструктор копии позволяет точно определить порядок создания копии объекта.
Любой конструктор копирования имеет следующую форму:
имя_класса (const имя_класса & obj)
{
... // тело конструктора
}
Здесь obj - это ссылка на объект или адрес объекта. (Подробнее использование ссылок рассмотрим немного позднее.) Конструктор копирования вызывается всякий раз, когда создается копия объекта. Мы уже рассмотрели два таких случая. Во-первых, при передаче объекта в качестве параметра функции. Во-вторых, при создании временного объекта тогда, когда функция в качестве возвращаемого значения использует объект. Есть еще один случай, когда полезен конструктор копирования, - это инициализация одного объекта другим.
class ClassName
{
public:
ClassName ()
{
cout << 'Работа конструктора \n';
}
ClassName (const ClassName& obj)
{
cout << 'Работа конструктора копирования\n';
}
~ClassName ()
{
cout << 'Работа деструктора \n';
}
};
main()
{
ClassName c1; // вызов конструктора
ClassName c2 = c1; // вызов конструктора копирования
}
Замечание: конструктор копирования не влияет на операцию присваивания.
Теперь, когда есть конструктор копирования, можно смело передавать объекты в качестве параметров функций и возвращать объекты. При этом количество вызовов конструкторов будет совпадать с количеством вызовов деструкторов, а поскольку процесс образования копий теперь стал контролируемым, существенно снизилась вероятность неожиданного разрушения объекта.
Помимо создания конструктора копирования есть другой, более элегантный и более быстрый способ организации взаимодействия между функцией и программой, передающей объект. Этот способ связан с передачей функцией не самого объекта, а его адреса.
Перегружаемые функции и операторы (overload)
Одна из ключевых черт полиморфизма в С++ - замещение или перегрузка операторов и функций.
Важным расширением, пришедшим из языка АДА, является то, что транслятор С++ различает функции не только по именам, но и по типу аргументов.
double power (double x) {return x*x;}
int power (int x) {return x*x;}
Или другой пример, связанный с некоторыми неудобствами, возникающими при использовании библиотечных функций из языка С: abs(), labs() и fabs() возвращают абсолютное значение, соответственно, целого, длинного целого и числа с плавающей точкой. Из-за того, что для трех типов требуются три типа функции (т.е. три разных имени), ситуация выглядит неоправданно усложненной. В тоже время в С++ можно "перегрузить" одно имя для трех типов данных.
int abs (int x) { return x<0 ? -x:x; } // 1
long abs (long x) { return x<0 ? -x:x; } // 2
double abs (double x) { return x<0 ? -x:x; } // 3
main()
{
cout << "абсолютная величина -1000" << abs(-1000) << "\n"; // вызов функции 1
cout << "абсолютная величина -1000L" << abs(-1000L) << "\n"; // вызов функции 2
cout << "абсолютная величина -1000.0" << abs(-1000.0) << "\n"; // вызов функции 3
}
В ранних версиях С++ нужно было явно формулировать, что функции будут перегружаться с помощью директивы overload. Теперь этого делать не нужно.
Одно из основных применений перегрузки функций - это достижение полиморфизма при компиляции программ, который воплощает в себе философию "один интерфейс, множество методов".
Технически все просто. Транслятор в своей работе использует внутренние имена функций, которые существенно отличаются от используемых в программе. Эти имена содержат в себе скрытое описание типов аргументов. С этими же именами работают программы компоновщика и библиотекаря. Исходя из этого, мы можем использовать функции с одинаковыми именами, лишь бы типы аргументов у них были разными. На этом основана реализация одной из граней полиморфизма.
_3d c;
c.x = x + b.x;
c.y = y + b.y;
c.z = z + b.z;
return c;
}
Мы включили описание прототипа оператора внутрь структуры (инкапсулировали). Определение (реализацию) кода вынесем. Доступ к элементам структуры осуществляется привычным образом - через ".".
Теперь мы вправе написать следующий фрагмент:
_3d A, B, C;
A.x = 1.0;
A.y = 1.0;
A.x = 1.0;
B = A;
C = A + B; // это эквивалентно вызову C = A.operator + (B); /operator +(...) - один из методов объекта A/
Существует еще ряд ограничений на замещение операторов по сравнению с замещением функций:
оператор должен уже существовать в языке (нельзя добавлять совершенно новые, выдуманные вами операторы); нельзя переопределять действия встроенных в С++ операторов при работе со встроенными типами данных; так, Вы не можете изменить способ работы оператора "+" при сложении целых чисел; запрещено замещать операторы ".", ".*", "?:", "::" и символы препроцессора "#".
И последнее замечание. При переопределении операторов нужно придерживаться простого правила, - переопределенный оператор должен реализовывать некоторое действие, сходное по смыслу с уже определенными операторами, имеющими такое обозначение. (Впрочем, то же самое справедливо вообще для переопределяемых функций). Конечно, ничто не мешает переопределить, например, оператор "+" для вашего типа таким образом, чтобы в момент его вызова на экран 18 раз выводилось сообщение "Спартак-Чемпион". Однако очевидно, что использование такого оператора неминуемо приведет к путанице и ошибкам.
С перегрузкой функций связана еще одна возможность С++. Она называется аргумент по умолчанию. Аргумент по умолчанию позволяет, если при вызове соответствующий аргумент не задан, дать параметру значение по умолчанию.
Если в программе предварительно описывается прототип функции, то аргументы по умолчанию указываются в этом прототипе.
Например,
void f (int i=0, int j=1); // прототип функции f (...)
...
void f (int i, int j)
{
... // тело функции
}
Теперь эту функцию можно вызывать тремя способами
f (); // i по умолчанию равно 0, j по умолчанию равно 1
f (10); // i равно 10, j по умолчанию равно 1
f (11, 22); // i равно 11, j равно 22
Задать значение j, установив i по умолчанию, нельзя. И вообще, все параметры по умолчанию должны находиться правее аргументов, передаваемых обычным путем.
Несколько слов об аргументах по умолчанию. Ими могут быть только константы или глобальные переменные.
Применение аргумента по умолчанию является простейшей формой перегрузки функций. Понятно, что функция при этом остается одна, следовательно, и алгоритм, реализуемый при вызове этой функции, - один. А в перегруженных функциях, могут быть, вообще говоря, реализованы различные алгоритмы.
| [назад] | [оглавление] | [вперед] |
Переопределение операторов с помощью дружественных функций
Механизм объявления дружественных функций часто используется при переопределении операторов.
Давайте вспомним, как раньше мы переопределяли операторы для класса _3d
class _3d
{
//...
_3d operator + (_3d b);
};
_3d _3d::operator + (_3d b)
{
_3d c;
c.x = x + b.x;
c.y = y + b.y;
c.z = z + b.z;
return c; }
А теперь посмотрим, как тот же самый оператор + можно переопределить с использованием дружественной функции.
class _3d
{
//...
friend _3d operator + (_3d &a, _3d &b);
};
_3d operator + (_3d &a, _3d &b)
{
_3d c;
c.x = a.x + b.x;
c.y = a.y + b.y;
c.z = a.z + b.z;
return c;
}
Давайте обсудим, в каких случаях для доступа к приватной части типов следует использовать элементы, а в каких - дружественные функции. Некоторые операции должны быть элементами - конструкторы, деструкторы и виртуальные функции, но, как правило, программист имеет возможность выбора.
При определении того, какой должна быть функция нужно руководствоваться простым правилом: операция, изменяющая состояние объекта класса, должна быть элементом, а не другом.
Все вышесказанное в полной мере относится и к способу переопределения операторов. Для операторов вроде "=", "++" и "+=" выражение слева ясно определено, и, по-видимому, естественно реализовать их как операции над объектом, обозначенным этим выражением. Напротив, если для всех операндов операции желательно иметь неявное преобразование, функция, реализующая его, должна быть дружественной, а не элементом. Часто именно так обстоит дело для функций, реализующих операторы "+", "-", "||" и др.
Например,
class X {...};
X x;
x=1+x; // т.е. x = 1.operator + (x); - ошибка
В этом случае использование функции элемента для переопределения оператора "+" в любом случае породит ошибку. Так что здесь было бы правильнее применять дружественную функцию.
Если преобразования типов не определяются, то, по-видимому, нет явных причин для предпочтения элемента дружественной функции. При прочих равных условиях, выбирайте элемент.
| [назад] | [оглавление] | [вперед] |
Полиморфизм
Слово полиморфизм греческого происхождения и означает "имеющий много форм". Полиморфизм - это свойство, которое позволяет одно и тоже имя использовать для решения нескольких технически разных задач. Применительно к ООП, целью полиморфизма, является использование одного имени для задания общих для класса действий. На практике это означает способность объектов выбирать внутреннюю процедуру (метод) исходя из типа данных, принятых в сообщении. Например, объект "Print" может получить сообщение, содержащее двоичное целое число, двоичное число с плавающей точкой или символьную строку. Имея дело с объектно-ориентированным языком, Вы вправе ожидать, что объект выполнит верные операции (или, по крайней мере, вежливо откажется от их выполнения) даже в случае, когда в момент составления программы возможность появления сообщения данного типа не предполагалась.
В более общем смысле, концепцией полиморфизма является идея "один интерфейс, множество методов". Это означает, что можно создать общий интерфейс для группы близких по смыслу действий. Преимуществом полиморфизма является то, что он помогает снижать сложность программ, разрешая использование одного интерфейса для единого класса действий. Выбор конкретного действия, в зависимости от ситуации, возлагается на компилятор.
Полиморфизм в языке С++ применим к функциям и к операциям (имеются в виду операции типа +, ==, [ ] и др.).
Т.о., полиморфизм означает присваивание действию одного имени или обозначения, которое совместно используется объектами различных типов, при этом каждый объект реализует действие способом, соответствующим его типу.
ООП = ИНКАПСУЛЯЦИЯ + НАСЛЕДОВАНИЕ + ПОЛИМОРФИЗМ и, что особенно проявляется в последнее время, ПРОГРАММИРОВАНИЕ, УПРАВЛЯЕМОЕ СОБЫТИЯМИ.
| [назад] | [оглавление] | [вперед] |
Полиморфизм и виртуальные методы
О классе, содержащем виртуальный метод, говорят как о полиморфном классе. В чем же преимущество полиморфных классов?
Самое главное в том, что полиморфные классы допускают обработку объектов, тип которых неизвестен во время компиляции. Функции, описанные в базовом классе как виртуальные, могут быть модифицированы в производных классах, причем связывание произойдет не на этапе компиляции (то, что называется ранним связыванием), а в момент обращения к данному методу (позднее связывание).
Виртуальные методы описываются с помощью ключевого слова virtual в базовом классе. Это означает, что в производном классе этот метод может быть замещен методом, более подходящим для этого производного класса. Объявленный виртуальным в базовом классе, метод останется виртуальным для всех производных классов. Если в производном классе виртуальный метод не будет переопределен, то при вызове будет найден метод с таким именем вверх по иерархии классов (т.е. в базовом классе).
Перепишем нашу иерархию классов.
class Point
{
...
public:
...
virtual void Show ();
virtual void Hide ();
void MoveTo (int newX, int newY);
};
...
реализация методов класса Point
...
class Circle: public Point
{
...
public:
... // без метода MoveTo()
virtual void Show ();
virtual void Hide ();
};
...
реализация методов класса Circle
...
Прежде всего, заметим, что в классе Circle нет метода MoveTo(), он наследуется из класса Point.
При этом все вызовы отложенных в MoveTo() методов будут методами класса Circle, так как они являются виртуальными методами.
Полнота.
Тип данных является полным, если он обеспечивает достаточно операций для того, чтобы все требующиеся пользователю работы с объектами могли быть проделаны с приемлемой эффективностью.
Строгое определение полноты дать невозможно, хотя существуют пределы относительно того, насколько мало операций может иметь тип, оставаясь при этом приемлемым. В общем случае абстракция данных должна иметь операции, по крайней мере, трех из четырех рассмотренных классов. Это примитивные конструкторы, наблюдатели и либо конструкторы, либо модификаторы.
Полнота типа зависит от контекста использования, т.е. тип должен иметь достаточно богатый набор операций для предполагаемого использования. Если тип предполагается использовать в ограниченном контексте, то нужно обеспечить достаточно операций только для этого контекста. Если тип предназначен для общего пользования, то желательно иметь более богатый набор операций. Однако чрезмерное количество операций в типе затрудняет понимание абстракций, и делает сложной ее реализацию. Введение дополнительных операций должно быть соотнесено с затратами на реализацию этих операций. Если тип является полным, его набор операций может быть расширен процедурами, функционирующими вне реализации типа.
| [назад] | [оглавление] | [вперед] |
Целью курса является дать представление
Целью курса является дать представление студентам об основных принципах объектно-ориентированного программирования на языке С++. Основной задачей курса является подготовка специалистов, владеющих современными методами и средствами разработки алгоритмов и программ, знающих современную технологию программирования и умеющих применять ее при решении сложных прикладных задач. Курс лекций расчитан на студентов, имеющих подготовку по информатике и программированию на языке С.
Если у вас есть каке-то замечания по поводу изложенного здесь материала - пишите.
Пример построения классов и наследования
В качестве примера выберем графические объекты, использование которых может оказаться полезным в самых различных сферах. Разумно начать с класса, который моделирует построение физических пикселов на экране.
struct Point
{
int X;
int Y;
};
Но пиксел на экране монитора, кроме координат своего положения, обладает еще и возможностью "светиться". Расширим структуру:
enum Boolean {false, true}; // false = 0, true = 1
struct Point
{
int X;
int Y;
Boolean Visible;
};
Тип Boolean хорошо знаком программистам на Паскале. Этот код использует перечисляемый тип enum для проверки true (истина) или false (ложь). Так как значения перечисляемого типа начинаются с 0, то Boolean может иметь одно из двух значений: 0 или 1 (ложь или истина).
Учитывая наш опыт работы со структурой _3d, мы должны позаботиться об интерфейсе класса Point. Нам будут необходимы методы для инициализации координат пикселя и указания, "включен" он или нет. Кроме того, если мы захотим сделать внутренние переменные недоступными, следует предоставить какой-либо способ узнать, что в них находится, прочитать их значения регламентированным образом. Следующая версия может выглядеть:
enum Boolean {false, true}; // false = 0, true = 1
class Point
{
protected:
int X;
int Y;
Boolean Visible;
public:
int GetX(void) { return X; }
int GetY(void) { return Y; }
Boolean isVisible (){ return Visible;}
Point (const Point& cp); // прототип конструктора копирования
Point (int newX =0, int new Y =0); // прототип конструктора
};
Point :: Point (int NewX, int NewY) // конструктор
{
X = newX; Y = newY; Visible = false;
}
Point :: Point (const Point& cp) // конструктор копирования
{
X = cp.X; Y = cp.Y; Visible = cp.Visible;
}
Теперь у нас есть возможность объявлять объекты типа Point:
Point Center(320, 120); // объект Center типа Point
Point *point_ptr; // указатель на тип Point
point_ptr = &Center; // указатель показывает на Center
Задание аргументов по умолчанию при описании прототипа конструктора дает нам возможность вызывать конструктор без аргументов или с неполным списком аргументов:
Point aPoint ();
Point Row[80]; // массив из объектов типа Point
Point bPoint (100);
Пока мы может создавать объекты класса Point и определять их координаты, но не можем пока их показывать. Так что необходимо дополнить класс Point соответствующими методами.
class Point
{
...
public:
...
void Show();
void Hide();
void MoveTo(int newX, int newY);
};
void Point::Show()
{
Visible = true;
putpixel (X,Y,getcolor());
}
void Point::Hide()
{
Visible = false;
putpixel (X,Y,getbkcolor());
}
void Point::MoveTo (int newX, int newY)
{
Hide ();
X = newX;
Y = newY;
Show ();
}
Теперь, когда у нас есть полноценный класс Point, можно создавать объекты-точки, высвечивать, гасить и перемещать их по экрану.
Point pointA (50,50);
pointA.Show ();
pointA.MoveTo (100,130);
pointA.Hide ();
Если потребуется создать класс для другого графического объекта, то можно выбрать один из двух способов: либо начать его реализацию "с нуля", либо воспользоваться уже готовым классом Point, сделав его базовым. Второй способ кажется более предпочтительным, поскольку он предполагает использование уже готовых модулей, все, что при этом нужно - это создать новый производный от Point класс, дополнив его новыми состояниями и методами и/или переопределив некоторые методы базового класса.
Давайте попробуем создать класс Circle для окружности. Окружность, в известном смысле, является жирной точкой. Она имеет все, что имеет точка (позицию X и Y и видимое/невидимое состояние) плюс радиус. По-видимому, класс Circle появляется, чтобы иметь только отдельный элемент Radius, однако не забывайте обо всех элементах, которые наследует Circle, являясь классом, порожденным из Point. Circle имеет X, Y, а также Visible, даже если их не видно в определении класса для Circle.
class Circle: public Point
{
int Radius; // private по умолчанию
public:
Circle ( int initX, int initY, int initR);
void Show ();
void Hide ();
void Expand (int deltaR);
void Contract (int deltaR);
void MoveTo (int newX, int newY);
};
Circle::Circle (int initX, int initY, int initR) // конструктор
:Point (initX, initY) // вызов конструктора базового класса
{
Radius = initR;
}
void Circle::Show ()
{
Visible = true;
circle (X,Y, Radius);
}
void Circle::Hide () // скрыть = зарисовать цветом фона
{
Visible = false;
unsigned int tempColor = getcolor ();
setcolor (getbkcolor());
circle (X,Y, Radius);
setcolor (tempColor);
}
void Circle::Expand (int deltaR)
{
Hide();
Radius += deltaR;
Show();
}
void Circle::Contract (int deltaR)
{
Expand (-deltaR);
}
void Circle::MoveTo (int newX, int newY)
{
Hide ();
X = newX;
Y = newY;
Show ();
}
main()
{
int graphDr = DETECT, graphMode;
initgraph ( &graphDr, &graphMode, "");
Circle C (150,200,50); // создать объект окружность с центром в т.(150, 200) и радиуса 50
C.Show(); // показать окружность
getch();
C.MoveTo (300,100); // переместить
getch();
C.Expand (50); // растянуть
getch();
C.Contract (70); // сжать
getch();
closegraph();
}
Поскольку класс Circle - производный от класса Point, то, соответственно, класс Circle наследует из класса Point состояния X, Y, Visible, а также методы isVisible(), GetX(), GetY(). Что касается методов Show(), Hide() и MoveTo() класса Circle, то необходимость их переопределения продиктована спецификой объектов нового класса, поскольку, например, показать окружность, - это не то же самое, что показать точку.
Заметьте, что методы Circle требуют доступа к различным элементам данных в классах Circle и Point. Рассмотрим Circle::Expand. Она требует доступа к Radius. Нет проблем. Radius определен как private в самом Circle. Поэтому Radius доступен любой функции элементов из класса Circle.
Теперь рассмотрим Circle::Hide и Circle::Show. Они требуют доступа к Visible из своего базового класса Point. В этом примере Visible имела protected доступ в Point. А Circle порождается с доступом public из Point. Поэтому, Visible имеет protected доступ в пределах Circle. Заметим, что если бы Visible определялась как private в Point, то она была бы недоступна для функций элементов Circle. Можно было бы сделать Visible c доступом public. Однако в таком случае Visible сделалась бы доступной для функций не являющихся элементами.
Присваивание объектов
Один объект можно присвоить другому, если оба объекта имеют одинаковый тип. По умолчанию, когда объект A присваивается объекту B, то осуществляется побитовое копирование всех элементов-данных A в соответствующие элементы-данные B. Если объекты имеют разные типов разные, то компилятор выдаст сообщение об ошибке. Важно понимать, одинаковыми должны быть имена типов, а не их физическое содержание. Например, следующие два типа несовместимы.
class ClassName1
{
int a, b;
public:
void set (int ia, int ib) {a=ia; b=ib;}
};
class ClassName2
{
int a, b;
public:
void set (int ia, int ib) {a=ia; b=ib;}
};
Так что попытка выполнить
ClassName1 c1;
ClassName2 c2;
c2 = c1;
окажется неудачной.
Важно понимать, что при присваивании происходит побитное копирование элементов данных, в том числе и массивов. Особенно внимательным нужно быть при присваивании объектов, в описании типа которых содержатся указатели. Например,
class Pair
{
int a, *b;
public:
void set (int ia, int ib) {a=ia; *b=ib;}
int getb (){return *b;}
int geta (){return a;}
};
main()
{
Pair c1,c2;
c1.set(10,11);
c2 = c1;
c1.set(100,111);
cout << 'с2.b = '<< c2.getb();
}
В результате работы программы получим "c2.b = 111", а не 11, как ожидалось.
Чтобы избежать такого рода недоразумений, используют перегруженный оператор присваивания, в которой явным образом описается (т.е. контролируется) процесс присваивания элементов-данных одного объекта соответствующим элементам-данных другого объекта.
class Pair
{
int a, *b;
public:
Pair operator = (Pair p)
{
a = p.a;
*b = *(p.b);
return *this;
}
...
};
А вот как теперь будет выглядеть наш пример с трехмерным вектором.
class _3d
{
double x, y, z;
public:
_3d ();
_3d (double initX, double initY, double initZ);
double mod () {return sqrt (x*x + y*y +z*z);}
double projection (_3d r) {return (x*r.x + y*r.y + z*r.z) / mod();}
_3d operator + (_3d b);
_3d operator = (_3d b);
};
_3d _3d::operator = (_3d b)
{
x = b.x;
y = b.y;
z = b.z;
return *this;
}
Наивно было бы предполагать, что для каждой новой переменной типа _3d создается копия функции, реализующей операторы "+" и "=". Каждая функция представлена в единственном экземпляре и в момент вызова получает один скрытый параметр - указатель на экземпляр переменной, для которого она вызвана. Этот указатель имеет имя this. Если используемая переменная не описана внутри функции, не является глобальной, то считается, что она является членом структуры и принадлежит рабочей переменной this. Поэтому при реализации функций операторов мы опускали путь доступа к полям структуры, для которой этот оператор будет вызываться.
В качестве аргументов функций-операторов выступают операнды, а возвращаемое значение - результат применения оператора. В частности для оператора "=" это необходимо, чтобы обеспечить возможность последовательного присваивания (a=b=c). Бинарные операторы имеют один аргумент - второй передается через указатель this. Унарные, соответственно, один - this.
Процедурная абстракция
Процедурная абстракция или процедура - наиболее известный в программировании тип абстракции. Всякий, кто применял для выполнения функции подпрограмму, реализовывал тем самым процедурную абстракцию. Процедуры объединяют в себе методы абстракции через параметризацию и спецификацию, позволяя абстрагировать отдельную операцию или событие.
Процедура выполняет преобразование входных аргументов в выходные. Более точно, это есть отображение набора значений входных аргументов в выходной набор результатов с возможной модификацией входных значений. Причем оба эти набора могут быть пусты.
Посмотрим, как же проявляются рассмотренные нами абстракции через параметризацию и спецификацию в процедурах, и выявим те преимущества, предоставляемые процедурной абстракцией.
Абстракция представляет собой некоторый способ отображения. При этом мы абстрагируемся от "несущественных" подробностей, описывая лишь те, которые имеют непосредственное отношение к решаемой задаче. Реализации абстракций должны быть согласованы по всем таким "существенным" подробностям, а в остальном могут отличаться. Разумеется, различие между существенным и несущественным зависит от конкретной решаемой задачи.
В абстракции через параметризацию мы абстрагируемся от конкретных используемых данных. Эта абстракция определяется в терминах формальных параметров. Фактические данные связываются с этими параметрами в момент использования этой абстракции. Значения конкретных используемых данных являются несущественными, важно только их количество и тип. Преимущество таких обобщений заключается в том, что они уменьшают объем программ и, следовательно, объем модификаций.
В абстракции через спецификацию внимание фокусируется на "поведении" - "то, что делается", несущественным же является то, "как" это делается. В этом состоит главное преимущество абстракции через спецификацию, что позволяет переходить к другой реализации без внесения изменений в программу, использующую данную процедуру.
Например, существует достаточно много разнообразных алгоритмов сортировки и предположим, что в вашей программе описана некоторая процедура = функция SORT, реализующая один из таких алгоритмов. Допустим, что по каким-то причинам Вас перестал удовлетворять запрограммированный вариант, в этом случае достаточно просто переписать тело этой самой SORT, не внося изменений в остальную часть программы (однако при условии, что сохранится тип обрабатываемых данных). В данном случае для общего выполнения программы считается несущественным механизм сортировки.
Абстракция через спецификацию наделяет структуру программы двумя отличительными особенностями.
1. Локальность
2. Модифицируемость
Локальность означает, что реализация одной абстракции может быть создана и рассмотрена без необходимости анализа реализации какой-либо другой абстракции. Принцип локальности позволяет составлять программу из абстракций, создаваемых людьми, работающими независимо друг от друга. Один человек может создать абстракцию, которая использует абстракцию, созданную кем-то другим. Для понимания и сопровождения программы, составленной из абстракций важно знать, что реализуют собой сами используемые абстракции, а не конкретные операторы их тел. Именно в этом и состоит игнорирование несущественной информации, коей является текст тел используемых процедур.
Вторая особенность - модифицируемость. Абстракция через спецификацию позволяет упростить модификацию программы. Если реализация абстракции меняется, но ее спецификация остается прежней, то эти изменения не повлияют на оставшуюся часть программы. Разумное определение необходимых абстракций на начальном этапе разработки с учетом возможных модификаций может значительно сократить объем работ.
Вот собственно и все, что я хотел рассказать о процедурной абстракции. Как Вы видите все представленное здесь, в общем-то, не является чем-то качественно новым, возможно лишь, что для многих из Вас это заставит по-иному смотреть на, казалось бы, привычные и понятные вещи. Язык С, с которым Вы достаточно хорошо знакомы, как впрочем, и все процедурные языки такого уровня, позволяет реализовывать процедурную абстракцию посредством написания функций. Однако до сих пор возможность добавлять в базовый уровень новых типов данных не подкреплялась введением новых операций с этими типами. Такая возможность предоставляется на уровне абстракции данных.
Простое внесение
Начнем с простой программы, обращающейся к стандартным средствам языка С, а затем преобразуем применяя для ввода-вывода средства библиотеки iostream. (Это был наш первый пример программы на С++)
| Вариант на стандартном С | Вариант на С++ | ||
| #include <stdio.h> int i; char buff[80]; printf ("Введите число:"); scanf("%d", &i); printf ("Введите символьную строку:"); gets (buff); printf ("Вы ввели число: %d\n Вы ввели строку: %s\n", i, buff); | #include <iostream.h> int i; char buff[80]; cout << "Введите число и символьную строку:"; cin >> i >> buff; cout << "Вы ввели число:" << i << "\n" << "Вы ввели строку:" << buff << "\n"; |
Оставим пока в стороне вопросы ввода (к этому мы еще вернемся), и остановимся на выводе информации.
Сообщения, выводимые программой, будут иметь вид:
Вы ввели число: 12
Вы ввели строку: My string
При этом, применяя стандартной библиотечной функций printf(), мы использовали в качестве одного из параметров этой функции строку формата, которая содержит два спецификатора: %d, %s, которые предписывают оператору printf() осуществить вывод целого числа и строки. Но все вы прекрасно знаете, что такая конструкция весьма чувствительна к ошибкам. Стоит только неправильно указать спецификатор типа или пропустить какой-либо из аргументов, то на выходе получается бессмыслица, а на поиск ее причин и исправление ошибки уйдет время.
И посмотрите, как все те же операции могут быть реализованы с применением iostream.
Данная программа выводит абсолютно то же самое, но отличается во всем остальном. Вывод в ней осуществляется в результате выполнения выражения, а не вызова отдельной функции типа printf(). Приведенное выражение называется выражением внесения, так как текст в данном случае вносится в выходной поток.
Давайте подробнее рассмотрим, как работает операция внесения во второй версии программы. Первым шагом к пониманию операции внесения будет расстановка скобок в выражении так, чтобы можно было понять, каким образом оно интерпретируется компилятором:
(((((cout<<"Вы ввели число:")<<i)<<"\n Вы ввели строку:")<< buff)<<"\n");
Объект cout - это предопределенный объект класса iostream, который используется для вывода. Корме него существуют еще
cin - стандартный поток ввода
cerr - поток для вывода сообщений об ошибках.
Когда компилятор разбирает приведенное выше выражение, он начинает с самого высокого уровня вложенности скобочной структуры и на этом уровне находит
cout<<"Вы ввели число:"
В процессе анализа этого выражения компилятор пытается отыскать функцию - operator<<(), имеющую в качестве левого операнда объект класса ostream, а в качестве правого - целое. Описание переопределяемой функции operator << (ostream &, char*) содержится в заголовочном файле iostream.h. Здесь компилятор С++ преобразует исходное выражение в более пригодное для дальнейшей обработки. В результате получается следующее
operator<<(cout, "Вы ввели число:")
Когда функция operator << (ostream &, char*) будет выполнена, она выведет свой аргумент (строку) и примет значение объекта cout (ее первый аргумент). "Вы ввели число:" выведется на экран, и подвыражением, находящимся на самом глубоком уровне вложенности, станет
cout << i
Теперь компилятор ищет функцию operator <<(ostream &, int). Мы уже говорили, что iostream содержит функции операторы для всех встроенных типов. Процесс продолжается до тех пор, пока выражение внесения не будет сведено к набору вызовов функции operatop << ().
В итоге, выполнение этой сточки приведет к последовательному вызову нескольких функций-операторов
| функции | левый операнд | правый операнд | возвращаемое значение |
| operator (ostream &, char*) | cout | "Вы ввели число:" | cout |
| operator (ostream &, int) | cout | i | cout |
| operator (ostream &, char*) | cout | "\n Вы ввели строку:" | cout |
| operator (ostream &, char*) | cout | buff | cout |
| operator (ostream &, char*) | cout | "\n" | cout |
Раннее и позднее связывание
Вернемся к примеру: для изображения и удаления окружности недостаточно родительских методов Point.Show() и Point.Hide(). Поэтому потребовалось написать новые, перекрывающие их методы Circle.Show() и Circle.Hide(). Теперь сравните метод Circle.MoveTo() и Point.MoveTo().
Кто видит разницу?
Разницы, по крайней мере, внешней, нет. А что произойдет, если мы не будем перегружать этот метод?
Да, скорее всего, по экрану будет двигаться не окружность, а точка. Дело в том, что для всех методов было применено так называемое раннее связывание. Раннее или позднее связывание - это термины, относящиеся к этапу, на котором обращение к процедуре связывается с ее адресом. В случае раннего связывания адреса всех функций и процедур известны в тот момент, когда происходит компоновка программы.
В большинстве традиционных языков программирования, включая и С, используется только раннее связывание. В противоположность этому, в случае позднего связывания адрес процедуры не связывается с обращением к ней до того момента, пока обращение не произойдет фактически, т.е. во время выполнения программы. Возвращаясь к нашему примеру. Если мы вызовем Point.MoveTo(), то будет вызываться Point.Show() и Point.Hide(). Только из-за этого мы вынуждены заменять Point.MoveTo() на внешне почти полностью аналогичную функцию Circle.MoveTo().
Логика компилятора очень проста, сначала он ищет метод с таким именем, определенным внутри данного класса. Если метод с таким именем не определен внутри класса, то компилятор обращается к базовому классу и ищет его там. Если найдет, то подставит в точки вызова адрес метода из родительского класса. Если не найдет, то поднимается все выше.
Методы, которые мы обсудили, называются статическими. Они являются статическими в том смысле, что компилятор размещает их и разрешает ссылки на них во время компиляции. Это достаточно мощные средства для организации сложных программ. Однако они являются далеко не лучшим методом для обработки методов.
Рассмотренные выше проблемы обусловлены разрешением ссылок на методы во время компиляции. Способ решения этой проблемы - разрешить такие ссылки во время выполнения, динамически.
Для того чтобы это стало возможным нужен специальный механизм - в языке С++ это виртуальные методы.
Виртуальные методы реализуют чрезвычайно мощное средство для обобщения, называемое полиморфизмом, о котором мы уже говорили. В нашем случае оно означает следующее: способ задания одноименного действия, которое распределяется вверх и вниз по иерархии объектов, с выполнением этого действия способом, соответствующим каждому объекту в иерархии.
Описанная нами простая иерархия графических фигур представляет собой хороший пример полиморфизма в действии. Каждый тип объекта (класса) в нашей иерархии представляет различный тип фигуры на экране - точку или окружность. Возможно, позднее вы захотите определить классы для других фигур, таких как линия, квадрат или дуги.
Мы можем написать метод для каждой фигуры, который изобразит эту фигуру на экране. В терминах ОО мышления можно сказать, что наши классы графических фигур имеют способность отображать себя на экране. То, каким образом объект класса должен изображать себя на экране, является различным для каждого класса. Точка рисуется с помощью программы изображения точки, которой не требуется ничего, кроме координат позиции и, возможно, цвета. Для изображения окружности требуется совершенно отдельная графическая программа, принимающая в расчет не только X и Y, но также и радиус. А для дуги нужны еще начальный и конечный угол и более сложная процедура прорисовки. Можно изобразить любую графическую фигуру, но механизм, посредством которого изображается каждая фигура, должен быть предопределен. При этом одно слово Show будет использоваться для изображения всех форм.
Различие между вызовом статического метода и вызовом виртуального метода - это различие между решением сейчас и отложенным, задержанным решением. Когда мы кодируем вызов статического метода, то, по-существу, говорим компилятору: "Ты знаешь, чего я хочу. Делай вызов". Вызов виртуального метода, с другой стороны, подобен тому, что мы говорим компилятору: "Ты не знаешь, чего я хочу - пока. Когда придет время запроси образец".
Давайте подумаем над этой метафорой в терминах нашей проблемы с MoveTo(). Вызов Circle.MoveTo() может идти только в одно место: ближайшую реализацию MoveTo() вверх по иерархии объектов. В нашем случае он вызовет Point.MoveTo(), поскольку это ближайшая реализация. Это решение будет осуществлено во время компиляции. Но когда MoveTo() вызовет Show(), то это другая история. Каждый класс фигур имеет свою собственную реализацию метода Show(), поэтому то, какая реализация Show() вызывается в MoveTo(), должно полностью зависеть от того, какой объект вызвал MoveTo().
Это и является причиной того, почему вызов Show() внутри MoveTo() должен быть задержанным решением: при компиляции кода для MoveTo() мы не можем решить, вызов какого Show() сделать. Информация недоступна во время компиляции, поэтому решение следует отложить до времени выполнения, когда можно запросить тип объекта вызывающего MoveTo().
Процесс, посредством которого вызовы статического метода разрешаются однозначно во время компиляции, называется ранним связыванием.
Во время раннего связывания вызывающий метод и вызываемый метод связываются при первом удобном случае, то есть во время компиляции.
При позднем связывании вызываемого метода и вызывающего метода они не могут быть связаны во время компиляции, поэтому специальный механизм на это место для их дальнейшего связывание, потом, когда вызов будет сделан фактически.
Развитие технологии и языков программирования. Истории ООП.
На заре появления вычислительных машин программирование, как область знания, находилось в зачаточном состоянии. Первые программы создавались посредством переключателей на панели компьютера. Очевидно, что такой способ подходил только для небольших программ. Затем программы стали писать на языке машинных команд, а изобретение ассемблера позволило писать уже сравнительно длинные программы. Следующий шаг был сделан в 1950 году, когда был создан первый язык программирования высокого уровня Фортран.
Теперь программисты могли создавать программы длиной до нескольких тысяч строк длиной. Однако язык программирования, легко понимаемый в простых программах, когда дело касалось больших программ, становился нечитаемым (и неуправляемым). Избавление от таких неструктурированных программ пришло после изобретения в начале 70-х годов языков структурного программирования (Алгол, Паскаль и С). Структурное программирование подразумевает точно обозначенные управляющие структуры, программные блоки отсутствие (или минимальное использование) операторов GOTO, автономные подпрограммы, в которых поддерживается рекурсия и локальные переменные. С появлением структурного программирования появилась возможность разбиения программы на составляющие ее элементы. Теперь уже один программист был в состоянии создать и поддерживать программу в несколько десятков тысяч строк диной.
Хотя структурное программирование и принесло выдающиеся результаты, даже оно оказалось несостоятельным, когда программа достигала определенной длины. Чтобы писать более сложную программу, необходим был новый подход к программированию. В итоге были разработаны принципы объектно-ориентированного программирования, которое аккумулировало лучшие идеи, воплощенные в структурном программировании, в сочетании с мощными новыми концепциями, позволяющими оптимально организовать ваши программы. ООП позволяет разложить проблему на связанные между собой задачи. Каждая проблема становится самостоятельным объектом, содержащим свои собственные коды и данные, которые относятся к этому объекту. В этом случае исходная задача в целом упрощается, и программист получает возможность оперировать с гораздо большими по объему программами.
С++ - это попытка решения разработчиками языка С задач объектно-ориентированного программирования. С++ был разработан сотрудником исследовательской лаборатории компанииAT&T Бьерном Страуструпом (Bjarn Stroustrup) в 1980 году. В своих исторических замечаниях Страуструп поясняет, почему в качестве базового языка был выбран С:
- многоцелевой, лаконичный и относительно низкого уровня;
- отвечает большинству задач системного программирования;
- "идет везде и на всем";
- пригоден в среде программирования UNIX.
Первоначальное название "С с классами" в 1983 году, по предложению Рика Масситти(Rick Mascitti), было изменено на С++. В этом же году С++ был впервые применен за пределами исследовательской группы. С 1980 года С++ претерпел два существенных изменения: в 1985 и 1990 годах. Первый рабочий проект языка С++ стандарта ANSI (American National Standarts Institute) был представлен в январе 1994 года.
14 ноября 1997 года Международная организация стандартизации (International Standarts Organization, ISO) утвердила стандарт С++. Бьерн Страуструп высоко оценил новый стандарт, отметив, что описанная в нем реализация гораздо ближе к идеалу, чем первоначальная версия языка. Ожидается, что фирмы-разработчики приведут свои продукты в соответствии со стандартом, что должно радикально улучшить переносимость написанных на С++ программ.
Шаблоны функций
Объявление шаблона функции начинается с заголовка, состоящего из ключевого слова template, за которым следует список параметров шаблона.
// Описание шаблона функции
template <class X>
X min (X a, X b)
{
return a<b ? a : b;
}
Ключевое слово class в описании шаблона означает тип, идентификатор в списке параметров шаблона X означает имя любого типа.
В описании заголовка функции этот же идентификатор означает тип возвращаемого функцией значения и типы параметров функции.
...
// Использование шаблона функции
int m = min (1, 2);
...
Экземпляр шаблона функции породит, сгенерированный компилятором
int min (int a, int b)
{
return a<b ? a : b;
}
В списке параметров шаблона слово class может также относится к обычному типу данных. Таким образом, список параметров шаблона <class T> просто означает, что Т представляет собой тип, который будет задан позднее. Так как Т является параметром, обозначающим тип, шаблоны иногда называют параметризованными типами.
Приведем описание шаблона функции
template <class T>
T toPower (T base, int exponent)
{
T result = base;
if (exponent==0) return (T)1;
if (exponent<0) return (T)0;
while (--exponent) result *= base;
return result;
}
Переменная result имеет тип Т, так что, когда передаваемое в программу значение есть 1 или 0, то оно сначала приводится к типу Т, чтобы соответствовать объявлению шаблона функции.
Типовой аргумент шаблона функции определяется согласно типам данных, используемых в вызове этой функции:
int i = toPower (10, 3);
long l = toPower (1000L, 4);
double d = toPower (1e5, 5);
В первом примере Т становится типом int, во втором - long. Наконец, в третьем примере Т становится типом double. Следующий пример приведет к ошибке компиляции, так как в нем используются разные типы данных:
int i = toPower (1000L, 4);
Шаблоны классов
Вы можете создавать шаблоны и для классов, что позволяет столь же красиво работать с любыми типами данных. Классическим примером являются контейнерные классы (т.е. классы, содержащие типы), например множества. Используя шаблон, можно создавать родовой класс для множеств, после чего порождать конкретные множества - цветов, строк и т.д.
Давайте сначала рассмотрим вполне тривиальный пример, просто чтобы привыкнуть к используемому синтаксису. Рассматриваемый далее пример - класс, который хранит пару значений. Принадлежащие функции этого класса передают минимальное и максимальное значения, а также позволяют определить, являются ли два значения одинаковыми. Еще раз повторю, что раз перед нами шаблон класса, то тип значения может быть почти любым.
template <class T>
class Pair
{
T a, b;
public:
Pair (T t1, T t2);
T Max();
T Min ();
int isEqual ();
};
Пока все выглядит также изящно, как и для шаблонов функций. Единственная разница состоит в том, что вместо описания функции используется объявление класса. Шаблоны классов становятся все более сложными, когда вы описываете принадлежащие функции класса. Вот, например, описание принадлежащей функции Min() класса Pair:
template <class T>
T Pair <T>::Min()
{
return a < b ? a : b;
}
Чтобы понять эту запись, давайте вернемся немного назад. Если бы Pair был обычным классом (а не шаблоном класса) и T был бы некоторым конкретным типом, то функция Min класса Pair была бы описана таким образом:
T Pair::Min()
{
return a < b ? a : b;
}
Для случая шаблонной версии нам необходимо, во-первых, добавить заголовок шаблона template <class T>
Затем нужно дать имя классу. Помните, что на самом деле мы описываем множество классов - семейство Pair. Повторяя синтаксис префикса (заголовка) шаблона, экземпляр класса Pair для целых типов, можно назвать Pair<int>, экземпляр для типа double - Pair<double>, для типа Vector - Pair<Vector>. Однако в описании принадлежащей функции нам необходимо использовать имя класса Pair<T>. Это имеет смысл, так как заголовок шаблона говорит, что Т означает имя любого типа.
Приведем текст остальных методов класса Pair. Описания методов помещаются в заголовочный файл, так как они должна быть видимы везде, где используется класс Pair.
// конструктор
template <class T>
Pair <T>::Pair (T t1, T t2) : a(t1), b(t2)
{}
// метод Max template <class T>
T Pair <T>::Max()
{
return a>b ? a : b;
}
// метод isEqual template <class T>
int Pair <T>::isEqual()
{
if (a==b) return 1;
return 0;
}
Ранее уже отмечалось, что шаблоны функций могут работать только для тех (встроенных) типов данных или классов, которые поддерживают необходимые операции. То же самое справедливо и для шаблонов классов. Чтобы создать экземпляр класса Pair для некоторого классового типа, например для класса X, этот класс должен содержать следующие общедоступные функции
X (X &); // конструктор копирования
int operator == (X)
int operator < (X);
Три указанные функции необходимы, так как они реализуют операции, выполняемые над объектами типа T в метода шаблона класса Pair.
Если вы собираетесь использовать некоторый шаблон класса, как узнать какие операции требуются? Если шаблон класса снабжен документацией, то эти требования должны быть в ней указаны. В противном случае придется читать первичную документацию - исходный текст шаблона. При этом учитывайте, что встроенные типы данных поддерживают все стандартные операции.
Шаблоны классов: не только для типов
Параметризовать некоторый класс так, чтобы он работал для любого типа данных - это только половина того, что шаблоны обеспечивают для классов. Другой аспект состоит в том, чтобы дать возможность задания числовых параметров. Это позволяет Вам, например, создавать объекты типов "Вектор из 20 целых", "Вектор из 1000 целых" или "Вектор из 10 переменных типа double".
Основная идея проста, хотя используемый синтаксис может показаться сложным. Давайте в качестве примера рассмотрим некоторый обобщенный класс Vector. Как и класс Pair, класс Vector содержит функции Min(), Max(), isEqual(). Однако в нем может быть любое количество участников, а не два. В класс Pair число участников фиксировано и задаются они в качестве аргументов конструктора. В шаблоне Vector вместо этого используется второй параметр заголовка шаблона:
template <class T, int n> class Vector
{
public:
Vector();
~Vector() {delete[] coord;}
void newCoord (T x);
T Max ();
T Min();
int isEqual();
private:
T *coord;
int current;
};
Значение n, заданное в заголовке шаблона не используется в описании класса, но применяется в описании его методов. Конструктор Vector, использующий значение n для задания размера массива, выглядит так:
// конструктор
template <class T, int n>
Vector <T, n>::Vector():
{
coord = new T[n];
current = 0;
}
// метод Max
template <class T, int n>
T Vector <T, n>::Max():
{
T result (coord[0]); // *
for (int i=0; i<n; i++)
if (result < coord[i]) // **
result = coord[i]; // ***
}
В конструкторе задается список инициализаций, устанавливающих начальные значения для двух элементов класса. Элемент coord инициализируется адресом динамически размещенного массива размером n и состоящего из элементов типа Т, а элемент current инициализируется значением 0.
Опять, заметим, что в качестве Т может выступать почти любой тип. Однако и в этом случае успешная реализация возможна лишь при определенных условиях - для объектов, чей тип передается в шаблон в качестве параметра, должны быть определены следующие операции
1. конструктор копирования (*),
2. оператор < (**), и > для метода Max(),
3. оператор = (***).
Имеется несколько вариантов использования шаблонов с параметрами-значениями для динамического размещения массивов различных размеров. Например, можно передать размер массива конструктору. Указание размеров объекта во время конструирования или путем обращения к некоторому методу действительно обеспечивает задание размера, однако такой способ не позволяет создать отдельный тип для каждого отдельного размера. Подход с использованием шаблона гарантирует, что размер становится частью типа. Так, Vector вектор с пятью элементами типа double является типом, отличным от Vector с четырьмя элементами типа double.
Хотите ли Вы, чтобы различные размеры были различными типами, зависит от ваших нужд. Если сравнение двух векторов с четырьмя и пятью координатами не имеет особого смысла, то было бы неплохо сделать их различными типами. Вместе с тем, в случае классов для матриц, Вы, возможно, не захотите иметь особый тип для каждого размера матриц, так как, например, умножение, работает с матрицами различных размеров. Если Вы столкнетесь с подобной проблемой, то Вам потребуются только разумные проверки времени выполнения, а не контроль типов при компиляции.
Хотя числовые параметры шаблонов часто используются для задания размеров различных элементов, как это было показано для класса Vector, этим их применение не ограничивается. Например, с помощью числовых параметров можно задавать диапазоны значений графических координат в графическом классе.
Шаблоны (параметризованные типы)
Шаблоны функций.
Требования к фактическим параметрам шаблона.
Отождествление типов аргументов.
Шаблоны классов.
Шаблоны классов: не только для типов.
Наследование в шаблонах классов.
Сегодня мы поговорим об очень полезном инструменте, реализованном в С++. Имя этому инструменту - шаблон (template). В чем же его полезность?
Использование шаблонов призвано, как и следовало ожидать, облегчить процесс написания полноценных программ, где под понятием "написание" подразумевается не только процедура первоначального написания кода программы, но и последующий за этим долгий процесс отладки, модификации и сопровождения, созданного вами программного продукта. Чем же шаблоны могут упростить процесс написания программ?
В прошлом мы дублировали и размножали части программ, используя простое, но эффективное средство - текстовый редактор. Сегодня С++ предлагает нам более совершенный способ дублирования, и имя ему - "шаблоны".
Наиболее распространенным поводом для дублирования фрагментов программ является необходимость реализовать некий новый объем кода, аналогичный уже написанному, но изменив типы данных (например, целые на целые длинные). Чаще всего для подобной операции с помощью программы-редактора повторяли текст программы еще раз и меняли типы данных. Программируя на С++, вы могли бы воспользоваться средствами переопределения и дать обеим функциям одно и тоже имя. Переопределение делает текст программы более наглядным, но не избавляет нас от необходимости повторять один и тот же алгоритм в нескольких местах.
Один из вариантов решения этой проблемы средствами языка С состоит в использовании макроподстановок. Хотя макроопределения и дает возможность выписывать текст программы только один раз, у этого метода имеются несомненные недостатки. Во-первых, это целесообразно только для очень простых функций. Во-вторых, макроподстановки не обеспечивают контроля типов, и тем самым, не дают возможности воспользоваться одним из важнейших преимуществ С++. В-третьих, макроподстановки - это не обращения к функциям, а прямая подстановка тела во все места, где они используются, а это может сильно увеличить размер исполняемой программы.
Механизм шаблонов предполагает более совершенное решение, позволяющее отделить общий алгоритм от его реализации применительно к конкретным типам данных. Вы можете составить текст программы подпрограммы сейчас, а используемые типы уточнять позднее. Это возможно, так как используемый тип данных является в этом случае параметром. Шаблоны сочетают в себе преимущества однократной подготовки фрагментов программы (аналогично макрокомандам) и контроль типов, присущий переопределяемым функциям.
В языке С++ имеются два типа шаблонов - шаблоны функций и шаблоны классов.
СОДЕРЖАНИЕ КУРСА
1. Типы данных
Современное понятие типа Базовые типы Основные конструкторы типов
2. Методология программирования
Декомпозиция и абстракция Абстракция через параметризацию Абстракция через спецификацию Процедурная абстракция Абстракция данных Классы операций Полнота
3. Введение в объектно-ориентированное программирование
Немного истории Объектно - ориентированная технология разработки программ Инкапсуляция Наследование Полиморфизм
4. Объектно-ориентированные расширения С++
Консольный ввод и вывод в С++ Введение в классы Перегружаемые функции и операторы (overload)
5. Классы и объекты
Встраиваемые функции Конструкторы и деструкторы Конструкторы с параметрами и перегрузка конструкторов Присваивание объектов Передача в функции и возвращение объекта Указатели и ссылки на объекты
6. Наследование в языке С++
Модификаторы наследования Конструкторы и деструкторы при наследовании Пример построения классов и наследования Совместимость типов
7. Дружественные функции
Переопределение операторов с помощью дружественных функций
8. Виртуальные методы
Раннее и позднее связывание Виртуальные функции Полиморфизм и виртуальные методы Указатели на базовые классы Абстрактный класс
9. Шаблоны (параметризованные типы)
Шаблоны функций Требования к фактическим параметрам шаблона Отождествление типов аргументов Шаблоны классов Шаблоны классов: не только для типов Наследование в шаблонах классов
10. Библиотека iostream
Простое внесение Выражение извлечения Создание собственных функций внесения и извлечения Функции библиотеки iostream Манипуляторы ввода -вывода Файловые и строковые потоки
Совместимость типов
Наследование предъявляет свои требования к правилам совместимости типов.
В добавление ко всему прочему, порожденный тип наследует совместимость со всеми типами предка. Эта расширенная совместимость имеет три формы:
между экземплярами объектов,
между указателями объектов,
между формальными и фактическими параметрами.
Однако во всех трех формах необходимо запомнить, что совместимость типов распространяется от потомка к предку. Другими словами, порожденные классы можно свободно использовать вместо классов предка, но не наоборот.
Например,
Point APoint, *ptrPoint;
Circle ACircle, *ptrCircle;
При наличии этих объявлений следующие присваивания являются законными:
APoint = ACircle;
Обратные присваивания незаконны.
Родительскому объекту можно присваивать объект любого порожденного им класса.
Чтобы было проще запомнить путь совместимости типов, давайте рассуждать таким образом:
1. источник должен полностью заполнять объект назначения,
2. порожденные типы содержат все, что содержат родительские типы посредством наследования. Следовательно, порожденный тип будет иметь или тот же размер, или (обычно) размер больший, чем его предок, но никогда не меньший размер.
Присваивание родительского объекта порожденному может оставить некоторые поля потомка неопределенными после присваивания. Что весьма опасно.
В предложениях присваивания будут копироваться только те поля, которые являются общими для обоих типов, то есть только поля предка.
Совместимость типов также действует между указателями на классы. Указатели на потомков можно присваивать указателям на предков по тем же общим правилам, как и для экземпляров объекта.
Формальный параметр объекта заданного класса может использовать в качестве фактического параметра объект такого же класса или любого порожденного класса. Например,
void Proc (Point param)
Тогда фактические параметры могут иметь тип Point, Circle и любой другой порожденный от них тип.
| [назад] | [оглавление] | [вперед] |
Современное понятие типа
Прежде чем приступать к изучению объектно-ориентированного программирования (ООП) вспомним ряд положений, без понимания которых невозможно понять парадигму ООП. Одной из основных посылок для понимания такого метода программирования является четкое представление о типах данных, которые Вы собираетесь использовать в своей программе.
А начнем мы разговор с вещей, которые большинство из Вас считает простыми и давно известными. Мы поговорим о базовых типах данных и о конструкторах новых типов, используемых в языке С. Для нас стало уже привычным в начале каждой программы, функции описывать переменные, c которыми мы собираемся оперировать. При этом Вы иногда обоснованно, иногда нет, присваиваете каждой переменной один из доступных в данном языке программирования типов. А почему нам доступны именно эти типы? Насколько адекватно они позволяют описывать моделируемый в программе мир? Можно ли использовать другие, более подходящие типы? На эти и множество других, еще не заданных вопросов, мы и попытаемся сегодня найти ответы.
Каждая используемая нами в программе переменная только тогда имеет смысл, когда может принимать какие-либо значения. Множество значений, которые может принимать переменная, играет столь важную роль для характеристики переменной, что оно называется типом переменной.
Понятие типа программного объекта образовалось постепенно из понятия типа, вошедшего в употребление для описания типов данных, над которыми выполняются операции в программе. На заре программирования типы данных определялись тем, какой машинный формат применялся для отображения данных. Программисты раньше говорили не о типе процессора и его частотных характеристиках, они говорили "Я работаю на машине с длиной слова 64 разряда". (Такой длиной слова обладали отечественные ЭВМ БЭСМ-6, в отличие от распространенных тогда копий с машин IBM/360, имеющих длину слова 32 разряда). Вскоре данные с плавающей точкой стали называть данными вещественного типа. Данным логического типа стали приписывать значения "истина" или "ложь", хотя они представлялись единицей или нулем в одном единичном разряде.
Современное понятие типа базируется на множестве значений, которые могут принимать переменные данного типа, и наборе операций, которые можно к ним применять.
Теперь перед нами встает вопрос: как правильно задать тип данных в программе, и каким образом типы данных можно представить в памяти машины? Прежде всего, следует различать классы типов данных. Самой важной отличительной чертой является структурность значений того или иного типа. Если значение не структурное, т.е. не распадается на компоненты, то оно называется скаляром. Остановимся вначале на таких типах.
Почти все современные языки программирования поддерживают целый, вещественный и литерный типы данных. Многие, кроме того, поддерживают булевский или логический тип.
Итак, хорошо знакомые нам типы char, integer, float:..
Создание собственных функций внесения и извлечения
Мы уже говорили, что операторы >> и << можно перегружать, причем, вы сами можете создать свои операторы извлечения и внесения для создаваемых вами типов.
В общем виде, операция внесения имеет следующую форму
ostream& operator << (ostream& stream, имя_класса& obj)
{
stream << ... // вывод элементов объекта obj
// в поток stream, используя готовые функции внесения
return stream;
}
Аналогичным образом может быть определена функция извлечения
istream& operator << (istream& stream, имя_класса& obj)
{
stream >> ... // ввод элементов объекта obj
// из потока stream, используя готовые функции внесения
return stream;
}
Функции внесения и извлечения возвращают ссылку на соответствующие объекты, являющиеся, соответственно, потоками вывода или ввода. Первые аргументы тоже должны быть ссылкой на поток. Второй параметр - ссылка на объект, выводящий или получающий информацию.
Эти функции не могут быть методами класса, для работы с которым они создаются. Если бы это было так, то левым аргументом, при вызове операции << (или >>), должен стоять объект, генерирующий вызов этой функции.
cout << "Моя строка"; а сout.operator << ("Моя строка"); // ошибка
Получается, что функция внесения, определяемая для объектов вашего класса, должна быть методом объекта cout.
Однако при этом можно столкнуться с серьезным ограничением, в случае, когда необходимо вывести (или ввести) значения защищенных членов класса. По этой причине, как правило, функции внесения и извлечения объявляют дружественными к создаваемому вами классу.
class _3d
{
double x, y, z;
public:
_3d ();
_3d (double initX, double initY, double initZ);
double mod () {return sqrt (x*x + y*y +z*z);}
double projection (_3d r) {return (x*r.x + y*r.y + z*r.z) / mod();}
_3d& operator + (_3d& b);
_3d& operator = (_3d& b);
friend ostream& operator << (ostream& stream, _3d& obj);
friend istream& operator >> (istream& stream, _3d& obj);
};
ostream& operator << (ostream& stream, _3d& obj)
{
stream << "x=" << obj.x<< "y=" << obj.y << "z=" << obj.z;
return stream;
}
istream& operator << (istream& stream, _3d& obj)
{
stream >> obj.x >> obj.y >> obj.z;
return stream;
}
main()
{
_3d vecA;
cin >> vecA;
cout << "My vector: " << vecA << "\n";
}
Хотя в функции внесения (или извлечения) может выполняться любая операция, лучше ограничить ее работу только выводом (или вводом) информации.
Типы данных
Современное понятие типа в языках программирования.
Базовые типы.
Основные конструкторы типов.
Требования к фактическим параметрам шаблона
Шаблон функции toPower() может быть использован почти для любого типа данных. Предостережение "почти" проистекает из характера операций, выполняемых над параметром base и переменной result в теле функции toPower(). Какой бы тип мы не использовали в функции toPower(), эти операции для нее должны быть определены. В противном случае компилятор не будет знать, что ему делать. Вот список действий, выполняемых в функции toPower() с переменными base и result:
1. T result = base;
2. return (T)1;
3. return (T)0;
4. result *= base;
5. return result;
Все эти действия определены для встроенных типов. Однако если вы создадите функцию toPower() для какого-либо классового типа, то в этом случае такой класс должен будет включать общедоступные принадлежащие функции, которые обеспечивают следующие возможности:
действие 1 инициализирует объект типа Т таким образом, что класс Т должен содержать конструктор копирования,
- действия 2 и 3 преобразуют значения типа int в объект типа Т, поэтому класс Т должен содержать конструктор с параметром типа int, поскольку именно таким способом в классах реализуется преобразование к классовым типам,
- действие 4 использует операцию *= над типом Т, поэтому класс должен содержать собственную функцию-operator *=().
- действие 5 предполагает, что в типе T предусмотрена возможность построения безопасной копии возвращаемого объекта (см. конструктор копирования).
Схема такого класса выглядит следующим образом:
class T
{
public:
T (const T &base); // конструктор копирования
T (int i); //приведение int к Т
operator *= (T base);
// ... прочие методы
}
Используя классы в шаблонах функций, убедитесь в том, что вы знаете, какие действия с ними выполняются в шаблоне функции, и определены ли для класса эти действия. Если вы не снабдили класс необходимыми функциями, возникнут различные невразумительные сообщения об ошибках.
Указатели и ссылки на объекты
До сих пор доступ к членам объекта осуществлялся, используя операцию ".". Это правильно, если вы работаете с объектом. Однако доступ к членам объекта можно осуществлять и через указатель на объект. В этом случае обычно применяется операция стрелка "->".
Указатель на объект объявляется точно так же, как и указатель на переменную любого типа.
Для получения адреса объекта, перед ним необходим оператор &.
main()
{
_3d A (2,3,4);
_3d *pA;
pA = &A;
double dM = pA->mod();
}
В С++ есть элемент, родственный указателю - это ссылка. Ссылка является скрытым указателем, и всегда работает просто как другое имя переменной.
Наиболее важное использование ссылки - передача ее в качестве параметра. Чтобы разобрать в том, как работает ссылка, рассмотрим для начала программу, использующую в качестве параметра указатель.
void ToZero (_3d *vec)
{
vec->set (0,0,0); // используется " -> "
}
main()
{
_3d A (2,3,4);
ToZero (&A);
}
В С++ можно сделать то же самое, не используя указатели, с помощью параметра-ссылки.
void ToZero (_3d &vec)
{
vec.set (0,0,0); // используется " . "
}
main()
{
_3d A (2,3,4);
ToZero (A);
}
При применении параметра-ссылки, компилятор передает адрес переменной, используемой в качестве аргумента. При этом не только не нужно, но и неверно использовать оператор "*". Внутри функции компилятор использует переменную, на которую ссылается параметр-ссылка.
В отличие от передачи в качестве параметра объекта, использование ссылки-параметра предполагает, что функция, в которую передан параметр, будет манипулировать не копией передаваемого объекта, а именно этим передаваемым объектом.
Параметры-ссылки имеют некоторые преимущества по сравнению с аналогичными альтернативными параметрами-указателями. Во-первых, нет необходимости получать и передавать в функцию адрес аргумента, адрес передается автоматически. Во-вторых, ссылки предлагают более понятный и элегантный интерфейс, чем неуклюжий механизм указателей.
Ссылки могут также использоваться в качестве возвращаемого значения функции. Обычно такой механизм применяется в сочетании со ссылкой - параметром или указателем this. Все эти случаи объединяет необходимость передачи измененного объекта через его адрес, а не путем возвращения копии такого объекта. Вспомним хотя бы пример с переопределением оператора "=", где в качестве возвращаемого значения выступала копия измененного оператором "=" объекта. Теперь мы знаем, что можно сделать проще и эффективнее, если возвращать ссылку на измененный объект.
_3d& _3d::operator = (_3d& b)
{
x = b.x;
y = b.y;
z = b.z;
return *this;
}
Использование в качестве возвращаемого значения ссылку гарантирует, что возвращаемым в качестве результата этой функции будет именно тот объект, который вызывал операцию "=", а не его копия.
| [назад] | [оглавление] | [вперед] |
Указатели на базовые классы
Область применения виртуальных функций не ограничивается случаями, аналогичными представленному выше. Другая сфера приложения виртуальных функций связана с использованием указателей на объекты. Особенность указателей в С++ состоит в том, что указатель, объявленный в качестве указателя на базовый класс, также может использоваться, как указатель на любой класс, производный от этого базового. Так что, в это смысле, возможно
Point pointObj (100,20); // объект базового класса
Circle circleObj (20,30,10); // объект производного класса
Point *pointPtr; // указатель базового класса
pointPtr = & pointObj; // указывает на объект базового класса
pointPtr = & circleObj; // указывает на объект производного класса
Поскольку через указатель на объект можно вызывать метод этого объекта, то следующая запись вполне законна.
pointPtr = & pointObj;
pointPtr->MoveTo(10,10);
Таким же образом можно обратиться и к методу объекта производного класса.
pointPtr = & circleObj;
pointPtr -> Expand(12);
Еще больший интерес представляет вызов виртуальных методов, используя этот указатель.
pointPtr = & pointObj;
pointPtr->Show(10,10); // вызов Show() объекта pointObj класса Point
pointPtr = & circleObj;
pointPtr->Show(10,10); // вызов Show() объекта circleObj класса Circle
Посмотрим, как это свойство виртуальных методов и указателей на объекты базового класса может быть полезно в наше примере с точками и окружностями.
Рассмотрим некоторую процедуру JumpFigure(), имитирующую "скачек" некоторого объекта на экране на заданную высоту h.
void JumpFigure (Point* AnyFigure, int h)
{
int oldX = AnyFigure->GetX();
int oldY = AnyFigure->GetY();
delay(100); // временная задержка на 0.1 сек
AnyFigure->MoveTo (oldX, oldY-h); // "прыжок"
delay(100); // временная задержка на 0.1 сек
AnyFigure->MoveTo (oldX, oldY); // на исходную позицию
}
Функции JumpFigure() можно передавать указатель на любой объект типа Point, либо на объект класса, порожденного из класса Point.
Как код функции JumpFigure() узнает, объект какого класса фактически передан ей? Да никак. JumpFigure() и не знает класс этого объекта. JumpFigure() только делает ссылку на идентификаторы, определенные в классе Point. Благодаря наследованию эти идентификаторы определены так же в любом классе, порожденном классом Point.
Методы GetX(), GetY(), Show() и MoveTo() фактически присутствуют в классе Circle, так же как и в Point, и будут присутствовать в любом будущем классе, определенном в качестве потомка как Point, так и Circle.
Методы GetX(), GetY() и MoveTo() статические методы. Это означает, что JumpFigure() знает адрес каждой процедуры еще во время компиляции.
С другой стороны, Show() - это виртуальный метод. Есть различные реализации Show() для Point и для Circle, и JumpFigure() не знает во время компиляции, какая реализация будет вызываться.
Короче говоря, когда JumpFigure() вызывается, она ищет адрес правильной реализации Show() в таблице виртуальных методов класса, переданного в AnyFigure. Если экземпляр имеет тип Point, то вызовется Point.Show(), если это объект класса Circle, то Circle.Show(). Решение будет принято в момент вызова.
Итак, мы достигли значительного результата. Теперь JumpFigure() может изобразить объект любого класса, порожденного классом Point, независимо от того, существовал ли данный класс при компиляции функции JumpFigure() или нет.
Виртуальные функции
Что же делать, если мы хотим, чтобы "наследник" вел себя отлично от "предка", сохраняя при этом свойство совместимости с ним? На этот случай существуют виртуальные методы.
Виртуальный метод - это метод, который, будучи описан в потомках, замещает собой соответствующий метод везде, даже в методах, описанных для предка, если он вызывается для потомка.
Адрес виртуального метода известен только в момент выполнения программы. Когда происходит вызов виртуального метода, его адрес берется из таблицы виртуальных методов своего класса. Таким образом, вызывается то, что нужно.
В чем же преимущество виртуальных методов? Самое главное в том, что они допускают обработку объектов, тип которых неизвестен во время компиляции.
Это новый способ мышления для С.
Предположим, вы написали пакет графических средств, который поддерживает различные типы фигур: точки, окружности, квадраты и т.п. может возникнуть необходимость написать в качестве части этого пакета подпрограмму, которая будет изображать графическую фигуру с помощью "мыши".
Старый способ заключается в написании отдельных процедур для изображения графических фигур всех типов. Написать единую процедуру для рисования всех этих фигур будет затруднительно: окружность не имеет сторон, квадрат имеет только одну длину стороны и др.
Наиболее искусные программисты будут передавать признак фигуры, а затем, например, с помощью оператора switch выбирать нужную подпрограмму.
А что делать, если вы вдруг решите включить новую фигуру, например, восьмиугольник (для рисования дорожных знаков).
В вашем switch 'е нет такого case, и даже если вы напишите необходимую для рисования функцию, вы не сможете ее вызвать (разве что добавите еще один case). Явный недостаток вашего пакета - без дополнительных затрат на модифицирование уже отлаженных подпрограмм он может работать только с типами данных, которые он знает, то есть которые были определены разработчиками.
А вот полиморфные методы, определенные только сейчас, могут быть объединены совместно с программой, которая была откомпилирована год назад. Виртуальные методы - ключ к решению этой проблемы.
Виртуальные методы
Раннее и позднее связывание.
Виртуальные функции.
Полиморфизм и виртуальные методы.
Указатели на базовые классы.
Абстрактный класс.
Встраиваемые функции
Итак, давайте вспомним наш пример.
struct _3d
{
double x, y, z;
double mod () {return sqrt (x*x + y*y +z*z);}
double projection (_3d r) {return (x*r.x + y*r.y + z*r.z) / mod();}
_3d operator + (_3d b);
};
_3d _3d::operator + (_3d b)
{
_3d c;
c.x = x + b.x;
c.y = y + b.y;
c.z = z + b.z;
return c;
}
Обратите внимание на то, где мы описываем тело того или иного метода. Методы mod() и protection() описаны вместе со своими телами непосредственно внутри структуры. Но можно поступить иначе: поместить прототипы метода внутрь структуры, а определение тела функции - вне структуры, как мы поступили с оператором "+".
Первый способ используется для простых и коротких методов, которые в дальнейшем не предполагается изменять. Так поступают отчасти из-за того, что описания классов помещают обычно в файлы заголовков, включаемые затем в прикладную программу с помощью директивы #include. Кроме того, при этом способе машинные инструкции, генерируемые компилятором при обращении к этим функциям, непосредственно вставляются в оттранслированный текст. Это снижает затраты на их исполнение, поскольку выполнение таких методов не связано с вызовом функций и механизмом возврата, увеличивая в свою очередь размер исполняемого кода (то есть такие методы становятся inline или встраиваемыми). Второй способ предпочтительнее для сложных методов. Объявленные таким образом функции автоматически заменяются компилятором на вызовы подпрограмм, хотя при добавлении ключевого слова inline могут подставляться в текст как и в первом случае.
Кроме представленного выше способа создания встраиваемых функций (записать тело метода непосредственно в структуре), есть еще один способ - вставить спецификатор inline перед определением метода:
inline _3d _3d::operator + (_3d b)
{
_3d c;
c.x = x + b.x;
c.y = y + b.y;
c.z = z + b.z;
return c;
}
Теперь оператор "+" станет встраиваемой функцией.
Встраиваемые функции действуют почти так же, как и макроопределения с параметрами, но имеют перед последними ряд преимуществ. Во-первых, inline методы обеспечивают более стройный способ встраивания в программу короткой функции. Во-вторых, компилятор С++ гораздо лучше работает со встраиваемыми функциями, чем с макроопределениями.
Важно понимать, что inlineне является командой для компилятора, это скорее просьба сделать метод встраиваемым. Если по каким-то причинам (например, при наличии в теле функции операторов цикла, switch или goto) компилятор не выполнит запрос, то функция будет откомпилирована как невстраиваемая.
Введение в классы
Вероятно одним из наиболее важных понятий С++ является класс. Класс - это механизм для создания новых типов. Более детально понятие класса мы обсудим позднее, а пока ограничимся лишь кратким обзором.
Синтаксис описания класса похож на синтаксис описания структуры.
class имя_класса
{
закрытые элементы - члены класса
public:
открытые элементы - члены класса
};
На что здесь следует обратить внимание?
Имя_класса с этого момента становится новым именем типа данных, которое используется для объявления объектов класса.
Члены класса - это переменные состояния и методы этого класса, иными словами членами класса могут быть как переменные, так и функции. Функции и переменные, объявленные внутри объявления класса, становятся членами этого класса. Функции-члены класса будем называть методами этого класса.
По умолчанию, все функции и переменные, объявленные в классе, становятся закрытыми (private) . Т.е. они доступны только из других членов этого класса. Для объявления открытых членов класса используется ключевое слово public. Все функции-методы и переменные, объявленные после слова public, доступны и для других членов класса, и для любой другой части программы, в которой содержится класс. В структурах по умолчанию все члены являются отрытыми. Так что, приведенные ниже примеры аналогичны.
struct _3d
{
double mod ();
double projection (_3d r);
private:
double x, y, z;
};
или
class _3d
{
double x, y, z;
public:
double mod ();
double projection (_3d r);
};
В С++ для создания объектов традиционно принято использовать ключевое слово class. Существование структур, вероятно, оправдано поддержанием совместимости с С. В наших примерах мы иногда будем использовать struct для создания класса, на практике, как правило, в этом нет необходимости.
Хотя функции mod() и projection(_3d r) объявлены в _3d, они еще не определены. Для определения метода - члена класса, нужно связать имя класса, частью которого является метод, с именем класса. Это достигается путем написания имени функции вслед за именем класса с двумя двоеточиями. Два двоеточия называют операцией расширения области видимости.
double _3d::mod ()
{
return sqrt (x*x + y*y +z*z);
}
double _3d::projection (_3d r)
{
return (x*r.x + y*r.y + z*r.z) / mod();
}
...
main()
{
_3d a, b;
double dPro, dMod;
dMod = a.mod();
dPro = b.projection(a);
}
Введение в объектно-ориентированное программирование
Развитие технологии и языков программирования. История ООП.
ОО технология разработки программ.
Инкапсуляция.
Наследование.
Полиморфизм.
Естественное стремление разработчиков программ - сократить время разработки, облегчить повторное использование отлаженных модулей и снизить издержки на сопровождение и модификацию программ.
Для достижения этих целей в отрасли создания программных комплексов используют методы и подходы управления процессом разработки. На разных этапах развития программной инженерии использовались различные технологии программирования - императивное программирование; модульное программирование; структурное программирование; программирование, управляемое данными; программирование, управляемое событиями; функциональное программирование; логическое программирование и т.п. Теперь невозможно принять участие в дискуссии, посвященной программированию, если не использовать термин "объектно-ориентированное программирование".
Что нового оно привнесло в методы разработки программ? На чем базируется? В каком направлении развивается? Вот вопросы, на которые мы попытаемся ответить (или, по крайней мере, выразим свое мнение на это счет).
Выражение извлечения
Как и внесение, извлечение выполняется в С++ переопределяемыми функциями-операторами, обращения к которым подставляются компилятором в зависимости от типов данных, используемых в выражении. Вернемся к нашему примеру.
Выражение извлечения в данной программе - это выражение, которое использует cin, предопределенный объект оператора iostream.
cin >> i >> buff;
При анализе этой конструкции компилятор ведет себя так же, как и при анализе выражения внесения, подставляя вызовы функции в соответствии с типами используемых переменных.
А что будет в случае ошибочного выражения? Конечно, ошибочные данные - это всегда ошибочные данные, и ни один язык не сможет их исправить. Но средствами языка можно создать программу, устойчивую к разрушительному действию ошибочных данных. Пусть, к примеру, наша программа ожидает на вводе строку "12 строчечка".
Если на вход поступит "строчечка 12", то программа будет в большом затруднении при попытке интерпретировать "строчечка" как число. Однако библиотека iostream, в отличие от scanf(), производит контроль ошибок после ввода каждого значения. Кроме того, iostream может быть расширена введением операторов для новых типов.
Одна из наиболее распространенных ошибок при использовании scanf() - это задание вместо адресов аргументов их значений. Другая распространенная ошибка - путаница в использовании модификаторов форматов. При работе с iostream такого не бывает, так как проверка соответствия типов - неотъемлемая часть процесса ввода-вывода. Компилятор обеспечивает вызов функций-операторов, строго соответствующих используемым типам.
